
介绍
注意,讲解的模块叫做 Pyppeteer,不是 Puppeteer。
Puppeteer 是 Google 基于 Node.js 开发的一个工具,有了它我们可以通过 JavaScript 来控制 Chrome 浏览器的一些操作,当然也可以用作网络爬虫上,其 API 极其完善,功能非常强大。
而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但他不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
环境部署
pip install
pip install pyppeteer -i https://pypi.douban.com/simple
- 1
chromium下载
国内无法访问 可以使用国内镜像
chromium下载地址:https://npm.taobao.org/mirrors/chromium-browser-snapshots/
下载之后解压之后,通过executablePath属性指定运行浏览器了
我这里上传了到了csdn你也可以从这下
https://download.csdn.net/download/qq_27648991/12513423
参考
可以参考puppeteer官方文档,因为pyppeteer的语法跟他一样
快速使用
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@time:2020/04/04
"""
import asyncio
from pyppeteer import launch
async def main():
# 浏览器 启动参数
start_parm = {
# 启动chrome的路径
"executablePath": r"C:\Users\yq\AppData\Local\pyppeteer\pyppeteer\local-chromium\722234\chrome-win\chrome.exe",
# 关闭无头浏览器 默认是无头启动的
"headless": False,
}
# 创建浏览器对象,可以传入 字典形式参数
browser = await launch(**start_parm)
# 创建一个页面对象, 页面操作在该对象上执行
page = await browser.newPage()
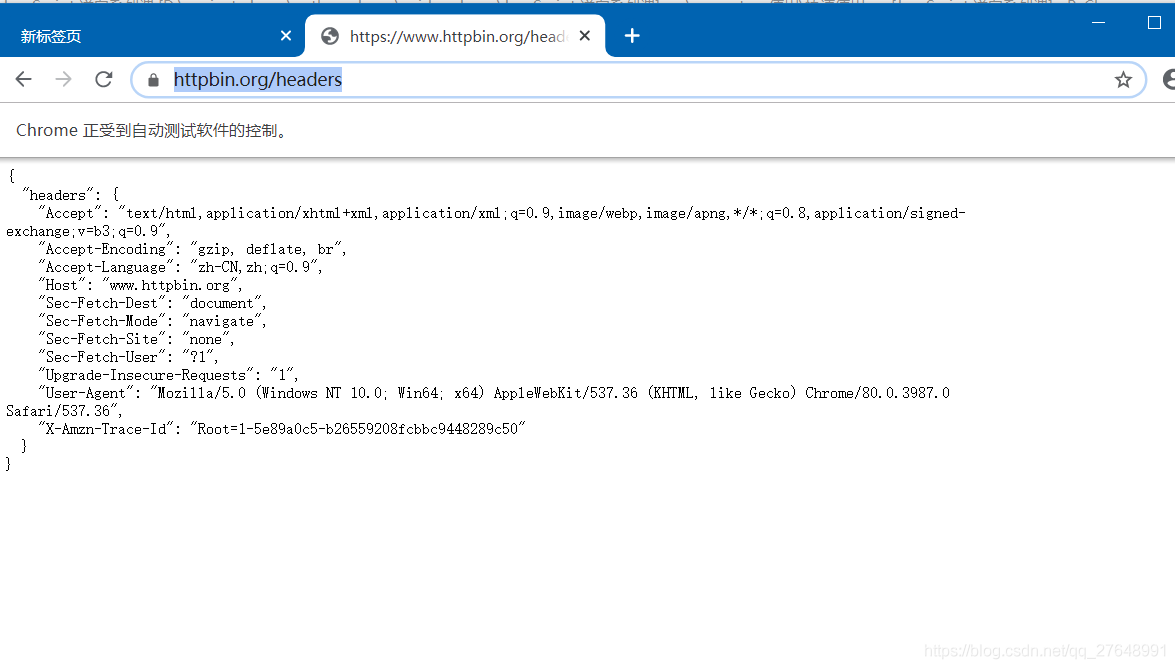
await page.goto('https://www.httpbin.org/headers') # 页面跳转
page_text = await page.content() # 页面内容
print(page_text)
input('==========')
await browser.close() # 关闭浏览器对象
asyncio.get_event_loop().run_until_complete(main()) # 创建异步池并执行main函数。
应用技巧
启动参数优化
常用的参数
总结常用的启动参数
| 属性 | 参数 | 描述 |
|---|---|---|
| executablePath | str | chrome.exe运行的路径 |
| ignorehttpserrrors | bool | 忽略https错误,默认false |
| headless | bool | True 开始无头浏览器 False关闭无头 |
| dumpio | bool | 设置True 解决浏览器多开卡死 (没有测试过) |
| 下面是args的参数设置 | 下面是args的参数设置 | 下面是args的参数设置 |
| –disable-infobars | – | 关闭自动化提示框 |
| –window-size=1920,1080 | str | 设置浏览器大小吗,1920是宽,1080是宽 |
| –log-level=30 | str | 日志保存等级, 建议设置越好越好,要不然生成的日志占用的空间会很大 30为warning级别 |
| –start-maximized | – | 窗口最大化模式 |
| –proxy-server=http://localhost:1080 | str | 设置代理 |
| userDataDir=D:\userData\ | str | 用户文件保存地址 |
其他参数
来源于网络copy的
- ignoreHTTPSErrors (bool): 是否要忽略 HTTPS 的错误,默认是 False。
- headless (bool): 是否启用 Headless 模式,即无界面模式,如果 devtools 这个参数是 True 的话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。
- executablePath (str): 可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。
- slowMo (int|float): 通过传入指定的时间,可以减缓 Pyppeteer 的一些模拟操作。
- args (List[str]): 在执行过程中可以传入的额外参数。
- ignoreDefaultArgs (bool): 不使用 Pyppeteer 的默认参数,如果使用了这个参数,那么最好通过 args 参数来设定一些参数,否则可能会出现一些意想不到的问题。这个参数相对比较危险,慎用。
- handleSIGINT (bool): 是否响应 SIGINT 信号,也就是可以使用 Ctrl + C 来终止浏览器程序,默认是 True。
- handleSIGTERM (bool): 是否响应 SIGTERM 信号,一般是 kill 命令,默认是 True。
- handleSIGHUP (bool): 是否响应 SIGHUP 信号,即挂起信号,比如终端退出操作,默认是 True。
- dumpio (bool): 是否将 Pyppeteer 的输出内容传给 process.stdout 和 process.stderr 对象,默认是 False。
- userDataDir (str): 即用户数据文件夹,即可以保留一些个性化配置和操作记录。
- env (dict): 环境变量,可以通过字典形式传入。
- devtools (bool): 是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为 True,那么 headless 参数就会无效,会被强制设置为 False。
- logLevel (int|str): 日志级别,默认和 root logger 对象的级别相同。
- autoClose (bool): 当一些命令执行完之后,是否自动关闭浏览器,默认是 True。
- loop (asyncio.AbstractEventLoop): 时间循环对象。
示例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@time:2020/04/04
"""
import asyncio
import logging
import tkinter
from pyppeteer import launch, launcher
from lxml import etree
async def main():
# 浏览器 启动参数
start_parm = {
# 启动chrome的路径
"executablePath": r"C:\Users\yq\AppData\Local\pyppeteer\pyppeteer\local-chromium\722234\chrome-win\chrome.exe",
# 关闭无头浏览器
"headless": False,
"args": [
'--disable-infobars', # 关闭自动化提示框
# '--window-size=1920,1080', # 窗口大小
'--log-level=30', # 日志保存等级, 建议设置越好越好,要不然生成的日志占用的空间会很大 30为warning级别
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36', # UA
'--no-sandbox', # 关闭沙盒模式
'--start-maximized', # 窗口最大化模式
# '--proxy-server=http://localhost:1080' # 代理
r'userDataDir=D:\project_demo\python_demo\spider_demo\JavaScript 逆向系列课\userdata' # 用户文件地址
],
}
await page.goto('https://www.httpbin.org/headers')
page_text = await page.content()
input('----------------')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
窗口/可视区最大化
但窗口设置最大化(–start-maximized)或窗口大小(–window-size=1920,1080)时,发现自己页面可视区域没有变化。成下面图片显示效果

设置可视化参数,代码如下
# !/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@time:2020/04/04
"""
import asyncio
import tkinter
from pyppeteer import launcher
# 注意 在导入launch之前先把默认参数改了
# 去除自动化 启动参数
launcher.AUTOMATION_ARGS.remove("--enable-automation")
from pyppeteer import launch
async def main():
# 浏览器 启动参数
start_parm = {
# 启动chrome的路径
"executablePath": r"C:\Users\yq\AppData\Local\pyppeteer\pyppeteer\local-chromium\722234\chrome-win\chrome.exe",
# 关闭无头浏览器
"headless": False,
"args": [
'--disable-infobars', # 关闭自动化提示框
'--no-sandbox', # 关闭沙盒模式
'--start-maximized', # 窗口最大化模式
],
}
browser = await launch(**start_parm)
page = await browser.newPage()
# 查看当前 桌面视图大小
tk = tkinter.Tk()
width = tk.winfo_screenwidth()
height = tk.winfo_screenheight()
tk.quit()
print(f'设置窗口为:width:{width} height:{height}')
# 设置网页 视图大小
await page.setViewport(viewport={'width': width, 'height': height})
await page.goto('https://www.baidu.com')
input('----------------')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这时就显示正常了。
隐藏浏览器特征
pyppeteer跟selenium一样会有浏览器特征,所以需要修改,隐藏特征防止被识别。
主要有下面两点:
- 去除浏览器自动化参数
--enable-automation - 去除
window.navigator.webdriver等检测
代码示例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@time:2020/04/04
"""
import asyncio
import logging
import tkinter
from pyppeteer import launcher
# 第一步 去除浏览器自动化参数
# 必须在 from pyppeteer import launch 前去除参数
# 去除自动化 启动参数
launcher.AUTOMATION_ARGS.remove("--enable-automation")
from pyppeteer import launch
from lxml import etree
async def main():
# 浏览器 启动参数
start_parm = {
# 启动chrome的路径
"executablePath": r"C:\Users\yq\AppData\Local\pyppeteer\pyppeteer\local-chromium\722234\chrome-win\chrome.exe",
# 关闭无头浏览器
"headless": False,
"args": [
'--disable-infobars', # 关闭自动化提示框
# '--window-size=1920,1080', # 窗口大小
'--log-level=30', # 日志保存等级, 建议设置越好越好,要不然生成的日志占用的空间会很大 30为warning级别
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36', # UA
'--no-sandbox', # 关闭沙盒模式
'--start-maximized', # 窗口最大化模式
# '--proxy-server=http://localhost:1080' # 代理
r'userDataDir=D:\project_demo\python_demo\spider_demo\JavaScript 逆向系列课\userdata' # 用户文件地址
],
}
browser = await launch(**start_parm)
page = await browser.newPage()
tk = tkinter.Tk()
width = tk.winfo_screenwidth()
height = tk.winfo_screenheight()
tk.quit()
await page.setViewport(viewport={'width': width, 'height': height})
# 第二步,修改 navigator.webdriver检测
# 其实各种网站的检测js是不一样的,这是比较通用的。有的网站会检测运行的电脑运行系统,cpu核心数量,鼠标运行轨迹等等。
# 反爬js
js_text = """
() =>{
Object.defineProperties(navigator,{ webdriver:{ get: () => false } });
window.navigator.chrome = { runtime: {}, };
Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] });
Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], });
}
"""
await page.evaluateOnNewDocument(js_text) # 本页刷新后值不变,自动执行js
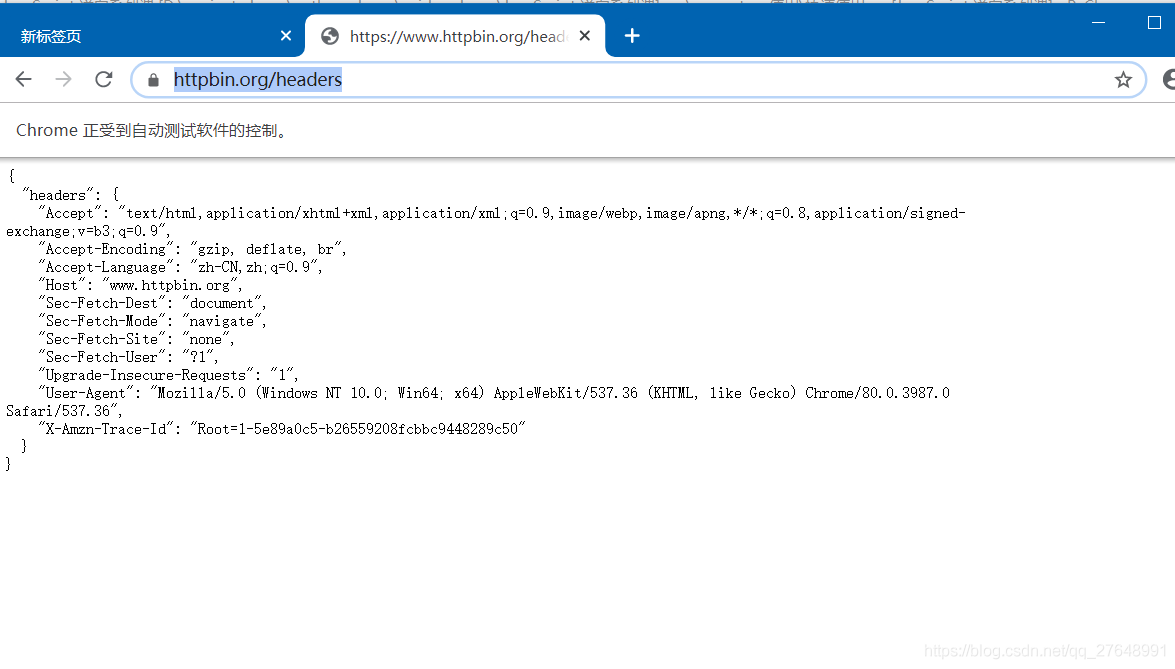
await page.goto('https://www.httpbin.org/headers')
page_text = await page.content()
print(page_text)
input('==========')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
拦截请求
可以对出现的请求,进行拦截 类似mitmproxy。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@time:2020/04/04
"""
import asyncio
import json
from jsonpath import jsonpath
from pyppeteer import launcher
launcher.AUTOMATION_ARGS.remove("--enable-automation")
from pyppeteer import launch
from pyppeteer.network_manager import Request, Response
async def intercept_request(req:Request):
await req.continue_() # 请求,看源码可以重新编写请求
async def intercept_response(res:Response):
if 'ext2020/apub/json/prevent.new' in res.url:
print('拦截到请求')
json_text = await res.text()
title_li = jsonpath(json.loads(json_text), '$..title')
for title in title_li:
print(title)
pass
async def main():
# 浏览器 启动参数
start_parm = {
# 启动chrome的路径
"executablePath": r"C:\Users\yq\AppData\Local\pyppeteer\pyppeteer\local-chromium\722234\chrome-win\chrome.exe",
# 关闭无头浏览器 默认是无头启动的
"headless": False,
"args": [
'--disable-infobars', # 关闭自动化提示框
# '--no-sandbox', # 关闭沙盒模式
'--start-maximized', # 窗口最大化模式
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
# UA
],
}
# 创建浏览器对象,可以传入 字典形式参数
browser = await launch(**start_parm)
# 创建一个页面对象, 页面操作在该对象上执行
page = await browser.newPage()
await page.setJavaScriptEnabled(enabled=True)
# 启用拦截器
await page.setRequestInterception(True)
page.on('request', intercept_request)
page.on('response', intercept_response)
js_text = """
() =>{
Object.defineProperties(navigator,{ webdriver:{ get: () => false } });
window.navigator.chrome = { runtime: {}, };
Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] });
Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], });
}
"""
await page.evaluateOnNewDocument(js_text) # 本页刷新后值不变,自动执行js
await page.goto('https://news.qq.com/') # 页面跳转
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) # 创建异步池并执行main函数。