
摘要:简单总结一下pyppeteer的使用方法,pyppeteer的强悍之处在于能过selenium不能过的,或许是越简单粗暴的越稳定?
介绍
Puppeteer是谷歌出品的基于Node.js开发的一款工具,pyppeteer是Puppeteer的python封装?Pyppeteer使用chromium浏览器(chrome的开源版)和asyncio框架
安装
python3使用国内源,然后直接使用pip3 install pyppeteer。
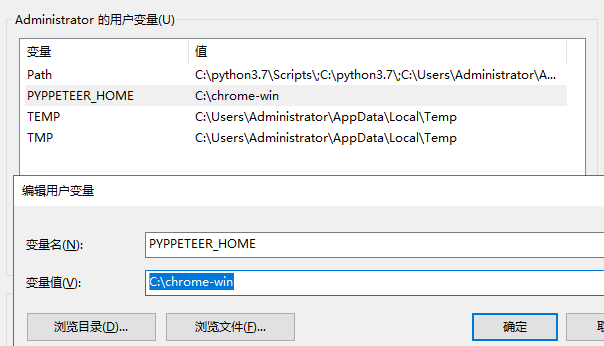
pyppeteer会自己下载一个chromium浏览器到C盘,但是我想自定义位置。(ps:下载chromium浏览器的功能是由pyppeteer.chromium_downloader完成的,自定义的方法来自于:网络爬虫之使用pyppeteer替代selenium完美绕过webdriver检测 – 奥辰 – 博客园)
在python3控制台界面运行如下代码:
import pyppeteer.chromium_downloader
print('默认版本是:{}'.format(pyppeteer.__chromium_revision__))
print('可执行文件默认路径:{}'.format(pyppeteer.chromium_downloader.chromiumExecutable.get('win64')))
print('win64平台下载链接为:{}'.format(pyppeteer.chromium_downloader.downloadURLs.get('win64')))输入如下:
默认版本是:588429
可执行文件默认路径:C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\local-chromium\588429\chrome-win32\chrome.exe
win64平台下载链接为:https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/588429/chrome-win32.zip在环境变量中设置PYPPETEER_HOME为C:\chrome-win

然后在运行上的代码输出如下:

可以看到可执行文件的默认路径变为:
C:\chrome-win\local-chromium\588429\chrome-win32\chrome.exechrome.exe的下载链接为
win64平台下载链接为:https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/588429/chrome-win32.zip然后在C盘下创建相应目录确保chrome.exe在可执行文件的默认路径就行了

使用例子
使用超级简单,但是关于asyncio框架我也只会个皮毛….
pyppeteer.launcher.launch
打开浏览器是通过pyppeteer.launcher.launch(options: dict = None, **kwargs) 方法,运行该函数后,会得到一个pyppeteer.browser.Browser实例,也就是说浏览器对象实例。launch方法是必须使用的方法。
- ignoreHTTPSErrors (bool): 是否HTTPS错误,某人情况下为False.
- headless (bool): 是否以无头模式(无界面模式)执行,默认为True,为True时是不会弹出可视界面的,所以,上面代码运行时设置headless=False。注意,下面还有个devtools参数,表示是否出现打开调试窗口,如果devtools设置为True,headless就算设置为False也会弹出可视界面。
- executablePath (str): Chromium或Chrome浏览器的可执行文件路径,如果设置,则使用设置的这个路径,不使用默认设置.
- slowMo (int|float): 设置这个参数可以延迟pyppeteer的操作,单位是毫秒.
- args (List[str]): 要传递给浏览器进程的一些其他参数.
- ignoreDefaultArgs (bool): 如果有些参数你不想使用默认值,那么,通过这个参数设置,不过,孩子,最好别用,有危险(电脑会爆炸).
- handleSIGINT (bool): 是否响应 SIGINT 信号,是否允许通过快捷键Ctrl+C来终止浏览器进程,默认值为True,也就是允许.
- handleSIGTERM (bool): 是否响应 SIGTERM 信号,也就是说kill命令关闭浏览器,,默认值为True,也就是允许.
- handleSIGHUP (bool): 是否响应 SIGHUP 信号,即挂起信号,默认值为True,也就是允许.
- dumpio (bool): 是要将浏览器进程的输出传递给process.stdout 和 process.stderr 对象,默认为False不传递。设置True 可以解决浏览器多开卡死
- userDataDir (str): 用户数据文件目录.
- env (dict): 以字典的形式传递给浏览器环境变量.
- devtools (bool): 是否打开调试窗口,上面介绍headless参数是说过,默认值为False不打开.
- logLevel (int|str): 日志级别,默认和 root logger 对象的级别相同.
- autoClose (bool): 当所有操作都执行完后,是否自动关闭浏览器,默认True,自动关闭.
- loop (asyncio.AbstractEventLoop): 时间循环。
- appMode (bool): Deprecated.
关于args的参数设置
| 属性 | 描述 |
|---|---|
| –disable-infobars | 关闭自动化提示框 |
| –window-size=1920,1080 | 设置浏览器的大小,1920是宽,1080是宽 |
| –log-level=30 | 日志保存等级 |
| –start-maximized | 窗口最大化模式 |
| –proxy-server=http://localhost:1080 | 设置代理 |
| userDataDir=D:\userData\ | 用户文件保存地址,可用于免登陆 |
简单使用
import asyncio
from pyppeteer import launch
async def main():
start_parm = {
"executablePath": r"E:\tmp\chrome-win\chrome.exe",
"headless": False,
}
browser = await launch(**start_parm)
page = await browser.newPage()
await page.goto('http://www.nows.fun/')
page_text = await page.content()
print(page_text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
设置窗口大小
ps:设置窗口大小有的时候能够躲避检测
关于window-size和viewport,一个是设置浏览器的大小,一个是设置网页的大小
import asyncio
from pyppeteer import launch
width, height = 1920, 1080
async def main():
browser = await launch(headless=False,
args=[f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.taobao.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())下面一个代码动态的根据显示屏屏幕调整:
import asyncio
from pyppeteer import launch
def screen_size():
"""使用tkinter获取屏幕大小"""
import tkinter
tk = tkinter.Tk()
width = tk.winfo_screenwidth()
height = tk.winfo_screenheight()
tk.quit()
return width, height
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
width, height = screen_size()
await page.setViewport({
"width": width,
"height": height
})
await page.goto('http://www.baidu.com/')
await asyncio.sleep(100)
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) 或者下面这个
import asyncio
import tkinter
from pyppeteer import launcher
launcher.AUTOMATION_ARGS.remove("--enable-automation")
from pyppeteer import launch
async def main():
start_parm = {
"executablePath": r"E:\tmp\chrome-win\chrome.exe",
"headless": False,
"args": [
'--disable-infobars',
'--no-sandbox',
'--start-maximized',
],
}
browser = await launch(**start_parm)
page = await browser.newPage()
tk = tkinter.Tk()
width = tk.winfo_screenwidth()
height = tk.winfo_screenheight()
tk.quit()
print(f'设置窗口为:width:{width} height:{height}')
await page.setViewport(viewport={'width': width, 'height': height})
await page.goto('http://www.nows.fun/')
page_text = await page.content()
print(page_text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
设置UA头
ps:设置UA头有的时候能够躲避检测
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3542.0 Safari/537.36')
await page.goto('http://www.baidu.com/')
await asyncio.sleep(100)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())关闭受控制提示
browser = await launch(headless=False, userDataDir='./userdata', args=['--disable-infobars']) 设置用户目录
比如淘宝登陆一次后,设置目录后下次打开淘宝会处于登陆状态,很方便。用的时候先手工在pyppeteer打开的浏览器中登陆一次。
browser = await launch(headless=False, userDataDir='./userdata', args=['--disable-infobars']) 执行js脚本
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://quotes.toscrape.com/js/')
await page.screenshot(path='example.png')
await page.pdf(path='测试.pdf')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) page.evaluateOnNewDocument和page.evaluate的区别
page.evaluateOnNewDocument: 永久注入js, 每次打开新页面注入。
await page.evaluateOnNewDocument('''() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => false,
});
}''');page.evaluate:当前页面注入, 页面跳转后js失效。
await page.evaluate('''() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => false,
});
}''');模拟操作
pyppeteer提供了Keyboard和Mouse两个类来实现模拟操作,前者是用来实现键盘模拟,后者实现鼠标模拟(还有其他触屏之类的就不说了)。
主要来说说输入和点击:
import os
os.environ['PYPPETEER_HOME'] = 'D:\Program Files'
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://h5.ele.me/login/')
await page.type('form section input', '12345678999')
await page.click('form section button')
await asyncio.sleep(200)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())上面的模拟操作中,无论是模拟键盘输入还是鼠标点击定位都是通过css选择器,似乎pyppeteer的type和click直接模拟操作定位都只能通过css选择器(或者是我在官方文档中没找到方法),当然,要间接通过xpath先定位,然后再模拟操作也是可以的。下一小节中模拟登陆外卖平台就是用这种方法,不过,这种方法要麻烦一些,不推荐。
某电商平台模拟登陆
这是我摘抄的, page.evaluate我认为是没用的。因为网页加载完成后,在运行js,感觉还是使用page.evaluateOnNewDocument最好。重点在于,看看作者对于xpath的用法就行。
我曾经用selenium + chrome 实现了模拟登陆这个电商平台,但是实在是有些麻烦,绕过对webdriver的检测不难,但是,通过webdriver对浏览器的每一步操作都会留下特殊的痕迹,会被平台识别,这个必须通过重新编译chrome的webdriver才能实现,麻烦得让人想哭。不说了,都是泪,下面直接上用pyppeteer实现的代码:
import os
os.environ['PYPPETEER_HOME'] = 'D:\Program Files'
import asyncio
from pyppeteer import launch
def screen_size():
"""使用tkinter获取屏幕大小"""
import tkinter
tk = tkinter.Tk()
width = tk.winfo_screenwidth()
height = tk.winfo_screenheight()
tk.quit()
return width, height
async def main():
js1 = '''() =>{
Object.defineProperties(navigator,{
webdriver:{
get: () => false
}
})
}'''
js2 = '''() => {
alert (
window.navigator.webdriver
)
}'''
browser = await launch({'headless':False, 'args':['--no-sandbox'],})
page = await browser.newPage()
width, height = screen_size()
await page.setViewport({
"width": width,
"height": height
})
await page.goto('https://h5.ele.me/login/')
await page.evaluate(js1)
await page.evaluate(js2)
input_sjh = await page.xpath('//form/section[1]/input[1]')
click_yzm = await page.xpath('//form/section[1]/button[1]')
input_yzm = await page.xpath('//form/section[2]/input[1]')
but = await page.xpath('//form/section[2]/input[1]')
print(input_sjh)
await input_sjh[0].type('*****手机号********')
await click_yzm[0].click()
ya = input('请输入验证码:')
await input_yzm[0].type(str(ya))
await but[0].click()
await asyncio.sleep(3)
await page.goto('https://www.ele.me/home/')
await asyncio.sleep(100)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())登录时,由于等待时间过长(我猜的)导致出现以下错误:
pyppeteer.errors.NetworkError: Protocol Error (Runtime.callFunctionOn): Session closed. Most likely the page has been closed.在github上找到了解决方法,似乎只能改源码,找到pyppeteer包下的connection.py模块,在其43行和44行改为下面这样:
self._ws = websockets.client.connect(
self._url, max_size=None, loop=self._loop, ping_interval=None, ping_timeout=None)再次运行就没问题了。可以成功绕过官方对webdriver的检测,登录成功,诸位可以自己尝试一下。
总结
当使用selenium+webdriver写爬虫被检测到时,pyppeteer是你得不二选择,几乎所有能在人工操作浏览器进行的操作通过pyppeteer都能实现,且能完美避开官方对webdriver的检测。pyppeteer涉及的使用方法还很多,本文只介绍了常用方法的很小很小一部分,需要一说的是,pyppeteer的中文资料真的很少,多看看官方文档吧。
参考
网络爬虫之使用pyppeteer替代selenium完美绕过webdriver检测 – 奥辰 – 博客园
Google推出的爬虫新神器:Pyppeteer,神挡杀神,佛挡杀佛!_个人文章 – SegmentFault 思否
Pyppeteer简介与案例
pyppeteer的环境搭建,常见参数及2个案例_崔永华的博客-CSDN博客