
欢迎来到我们每年一度的Python顶级库列表的第9版,这还不是一个完整的十年!随着我们在不断发展的Python开发领域中的旅程,是时候再次聚焦今年引起我们注意的杰出库和工具了。自2015年的第一版以来,我们致力于探索Python生态系统的深度,今年也不例外。事实上,这一年很特别——2023年标志着生成式人工智能和大型语言模型(LLMs)的繁荣,这一趋势对我们的选择产生了重大影响。
请参阅此系列中的其他帖子:2022年,2021年,2020年,2019年,2018年,2017年,2016年,2015年。
我们的标准保持一致:我们正在寻找在过去一年中推出或崭露头角的库和工具。要符合我们的首选,它们需要得到良好的维护,创新,并且当然要足够酷以激发您的兴趣。今年,您会注意到我们强调与LLM浪潮相一致的库,反映了这些技术如何重塑Python(或者我们应该说编程?)的格局。

但不要担心,我们的选择中仍然关注多样性!尽管每年都越来越困难,但我们努力确保我们的完整列表不仅适用于人工智能爱好者,还包含对广大Python开发者有价值的宝藏,包括一些小众应用。
我们发布这篇文章的目的也是为了引发关于我们可能忽视的出色图书馆和工具的讨论。
所以,怀着迫不及待的期待,让我们一起潜入2023年的Python世界吧!
10个主要选择
LiteLLM – 使用OpenAI格式呼叫任何LLM,以及更多

想象一个世界,你不被限制在特定的模型提供商上,切换LLMs就像改变一行或零行代码那样简单,而不是使用像LangChain这样的工具重写整个堆栈。LiteLLM使这成为现实。
LiteLLM的直观且不侵入式的设计允许与各种模型无缝集成,无论底层LLM如何,都提供统一的输入和输出格式。对于需要快速适应不断变化的大型语言模型领域的开发人员来说,这种灵活性是一个改变游戏规则的因素。
但 LiteLLM 不仅仅是灵活性,它还关乎效率和控制。流式响应和将异常映射到 OpenAI 的格式等功能展示了其强大性。特别值得注意的是,能够跟踪和管理不同LLMs的成本,确保您的 AI 探索不会导致意外的账单。在 API 调用可能迅速累积成本的领域中,这种财务控制水平至关重要。
此外,LiteLLM还配备了一个代理API服务器,增强了其在不改变任何代码的情况下与代码库集成的灵活性✨。
另一个区别特点是内置的负载均衡和速率限制功能。这些功能确保在处理多个推理调用的大量请求时实现最佳性能和资源利用。负载均衡有效地分发传入的API调用,防止任何单个模型提供者成为瓶颈。同时,速率限制功能在维持对模型的稳定和受控访问方面起着关键作用,防止过度使用和潜在的超载(忘掉HTTP 429)。
当然,细节决定成败:不同的LLM提供商的提示方式会有所不同,因此如果你真的想要利用不同的提供商,你需要做一些工作。但是,拥有一个可靠的层可以使切换变得尽可能容易,这是很好的。
为LiteLLM的作者们欢呼和祝贺。无论您是经验丰富的AI开发者还是刚刚开始尝试生成式AI,LiteLLM都是一个必备的工具库!
PyApp – 在任何地方部署自包含的Python应用程序
多年来,Python的流行已经不再是秘密。它的简单性和高效性的结合,再加上庞大友好的社区,使其成为全球使用最广泛的编程语言之一。然而,分发Python应用程序仍然是一个长期存在的挑战。与其他允许分发独立编译二进制文件的语言不同,Python在这个领域一直存在困难,特别是在面向非技术用户时。传统上,Python应用程序是通过Docker容器镜像共享的,这种方法并不总是适用于所有用户。
进入PyApp:一个简化Python应用程序分发和安装的实用库。它通过将Python嵌入到一个自安装的包中来实现这一目标,该包在所有操作系统上都兼容。但它并不止于此!PyApp还支持自更新功能,并可以根据各种用例进行定制。
使用PyApp,通过 requirements.txt 文件指定pip安装的依赖项非常简单,并且可以使用 .in 文件无缝地嵌入其他文件。该库处理安装过程,为Python和应用程序所需的依赖项创建一个专用目录。在后续运行中,PyApp检查该安装目录是否存在,优化命令行界面的响应速度。
它与您可能了解的其他工具(如PyInstaller)有所不同,PyApp不会进行依赖项发现,而是依赖于显式声明的依赖项,这似乎解决了一些用户面临的问题。
简而言之,PyApp为将Python应用程序交付给用户提供了一种简单而强大的解决方案。它简化了分发和安装过程,消除了通常与这些过程相关的障碍。展望2024年,毫无疑问,PyApp是一个值得加入你的Python工具库的工具,使Python应用程序的分发变得轻而易举!
3. Taipy-在生产环境中构建数据应用的用户界面

在时尚设计师乔治·阿玛尼的智慧言辞中,”优雅不是为了被注意,而是为了被记住”。这一哲学是Taipy的指导之星,Taipy是一个Python库,赋予数据科学家们从数据中编织引人入胜的叙事能力。
在数据科学领域,讲故事的艺术与底层模型一样重要。拥有合适的工具可以起到决定性的作用。这就是Taipy的作用。Taipy是一个低代码Python库,使数据科学家能够为他们的机器学习产品构建交互式Web用户界面,而无需掌握Web堆栈工具。这一切都是为了让数据科学家专注于他们最擅长的事情 – 从数据中提取洞察。
Taipy的魔力在于它能够将变量和表达式与UI中的可视组件的状态绑定在一起。这种绑定发生在声明可视组件时,大大减少了开发应用程序所需的样板代码。而且说到可视组件,Taipy提供了丰富的选项,包括图表、滑块和图像网格,帮助您构建下一代的用户界面。
但是等等,我们不是已经有了Streamlit(我们2019年的第7选择)吗?嗯,这就是Taipy的亮点所在。与Streamlit不同的是,Taipy在检测到输入变化时不会重新运行整个页面的代码,而是使用回调函数来仅更新受到变化影响的组件(就像R语言中的shiny一样,对于那些来自我们的兄弟语言的人来说),从而增强了响应性并加快了开发速度。
但创新并不止于此。Taipy还提供了用于可视化组合机器学习流程的工具,加快了开发速度,同时提供了一种简单的方式来高层次地解释模型所采取的步骤。重要的是,数据节点,即这些可视化流程的输入,可以动态改变,实现交互式探索和假设情景。
无论您选择自托管Taipy应用程序还是使用Taipy Cloud进行无服务器部署,您都将获得无缝体验。Taipy帮助您揭示数据中隐藏的故事,并创建令人难忘的、交互式的机器学习工作流程。立即查看!
这是他们2023年在PyData Seattle的演示,这是他们在HackerNews上发布的启动帖子;务必查看讨论中关于该库的一些有趣信息。
4. MLX – 在苹果芯片上进行机器学习,具有类似NumPy的API
2021年,苹果推出了其M1架构,现在进一步改进为当前的M3,这是一款革命性的硬件,带来了性能和效率的提升,以及一个统一的内存缓冲区,可以由CPU、GPU和NPU(苹果的神经引擎)访问,无需在处理单元之间复制信息。
2023年,关注的焦点是苹果的MLX,这是一个专为苹果芯片上的机器学习而设计的开创性的阵列框架。由苹果自己的机器学习研究团队提供,MLX正在为在Mac硬件上开发和部署机器学习模型设立新的标准。
MLX旨在保持熟悉性:它的Python API与NumPy非常相似,并且还提供了一个功能齐全的C++ API,与其Python版本相对应。像 mlx.nn 和 mlx.optimizers 这样的高级包遵循PyTorch的步伐,使得构建复杂模型变得轻而易举。
但是MLX不仅仅是一个熟悉的面孔。它引入了创新的功能,如可组合的函数转换,实现自动微分、自动向量化和计算图优化。它还采用了延迟计算,只在需要时才生成数组,并且采用动态图构建,使调试更直观,避免了由于函数参数形状变化而导致的编译速度慢。
MLX的多设备能力允许操作在任何支持的处理单元上运行,无论是CPU、GPU还是NPU。而这就是改变游戏规则的地方:MLX的统一内存模型。与其他框架不同,MLX数组存在于共享内存中,可以在任何支持的设备上进行操作,而无需进行耗时的数据传输。
这个用户友好且高效的框架是由机器学习研究人员为机器学习研究人员设计的。受到NumPy、PyTorch、Jax和ArrayFire等框架的启发,MLX旨在使研究人员能够轻松扩展和改进框架,促进对新想法的快速探索。
随着我们迈向2024年,MLX绝对是一个值得关注的工具包。无论您是苹果迷、机器学习爱好者还是两者兼而有之,MLX都将彻底改变您的机器学习之旅,并充分利用苹果芯片的能力。
5. Unstructured – 文本预处理的终极工具包

在人工智能的广阔领域中,模型的好坏取决于它所依赖的数据。但是当你的数据是一堆混乱的原始文件,分散在各种格式中时,会发生什么呢?那就使用Unstructured,一个全面的解决方案,满足你所有的文本预处理需求。
非结构化数据是释放原始数据潜力的关键,能够处理任何输入的内容——PDF文件、HTML文件、Word文档,甚至是图片。它就像是您数据的美食大厨,将其切割成适合AI模型的可口碎片。
非结构化提供了一个琳琅满目的功能,整齐地分为六种类型:
将原始文档转化为结构化和标准化格式的分区函数。
清理功能,可以去除不需要的文本,只留下相关的要点。
准备数据的分段函数,使其适用于机器学习任务,如推理或标注。
提取功能可以在文档中挖掘有价值的信息,例如电子邮件、IP地址或模式匹配的文本。
将文档分解为适合相似性搜索和RAG的小节的分块函数。
嵌入函数将预处理文本转换为向量,并提供易于使用的接口。
但这还不是全部。Unstructured还配备了Connectors,这是一套与各种存储平台无缝集成的工具。从GCS和S3到Google Drive、One Drive、Notion等等。这些Connectors可以双向工作,允许您从各种来源读取和写入信息。
Unstructured是您处理文档中无结构文本提取的Python库。它简化了文本清洗,处理从去除项目符号到管理表情符号和语言翻译的所有内容。其提取器函数解析清洗后的文本,提取有价值的信息。您可以使用内置的提取器或自定义模板来处理结构化文本。
图书馆的分期功能将预处理的文档保存为多种格式,与Label Studio和Prodigy等各种工具兼容。它还具有一个分块器,通过标题将文本分组为连贯的相关部分,并使用流行的LLM模型进行简单的文本向量化嵌入功能。
凭借Unstructured在您的工具包中,您将踏上大型语言模型的世界,这将是一个有回报的旅程。准备好在2024年释放您的数据的全部潜力吧!
6. ZenML和AutoMLOps – 可移植、生产就绪的MLOps流程

好的,我们在这里有点打破规则。两个图书馆,一个入口。但请相信我们,这将是值得的。
MLOps是机器学习模型开发和运营之间的关键环节。它实现了从实验阶段到生产就绪模型的平稳过渡。没有MLOps,组织将面临效率低下、资源浪费和预测不可靠的雷区。它确保了模型的可复现性、可扩展性和监控,将卓越的理论转化为有价值的解决方案。因此,有效的MLOps是成功的机器学习项目的支撑。
然而,建立一个有效的MLOps流水线往往感觉像是一项艰巨的任务。所需的服务和技能的广泛范围可能使整个过程变得令人生畏且耗时。此外,定制开发往往与应用逻辑紧密结合,导致维护应用代码变得具有挑战性。
这些选择旨在缓解这些问题,并将MLOps最佳实践置于您的开发核心。
ZenML为从实验性代码过渡到结构化、可投入生产的流水线提供了快速通道,只需进行最少的更改。这个与供应商无关的框架擅长将应用程序代码与基础设施工具分离,允许您为基础设施的每个组件指定不同的服务提供商。
使用ZenML,您的流水线步骤被注释并链接在一起形成实际的流水线。然后,您配置一个Zen Stack,指定必要的工具和基础设施。这个堆栈由两个主要组件组成:编排器和工件存储。编排器可以是云执行服务或简单的Python解释器,用于运行您的流水线代码。工件存储是您的数据所在的地方。最棒的是,ZenML支持多种集成,提供额外的功能,如特征存储、数据验证和实验跟踪器。
在另一方面,我们有谷歌的AutoMLOps,它与ZenML的方法类似,将模型开发代码注释为组件和流水线。然而,AutoMLOps更进一步,通过自动生成必要的代码来将您的组件容器化,将它们提供给谷歌的云端,并将这些容器部署到分配的资源上。所有这些都遵循自动化、可重复的CI/CD流程,有助于加速您迈向MLOps成熟度水平2的道路。
部署的管道可以利用谷歌的扩展MLOps功能套件,包括数据处理和存储、实验、训练和离线评估,以及具有可配置自动扩展能力的在线服务、测试和监测,以及对输入数据和模型预测的漂移进行监测。这使得可以使用连续训练和部署等高级功能,提高应用的准确性,并在对最终用户或业务产生真正影响之前捕捉错误。
专为利用Google Cloud Services和Vertex AI而量身定制的AutoMLOps是您在云端的魔毯之旅。虽然这个工具明显以Google为中心,但为了您将获得的巨大好处,这是一个小小的让步。如果您愿意使用Google Cloud,那么您的旅程将得到大大简化,使您的基于云的努力比以往更高效、更愉快。
凭借这两个强大的工具,您将能够应对MLOps的复杂性,确保您的机器学习项目不仅成功,而且高效可管理。
告别与基础设施和应用程序代码纠缠的日子,迎接高效的MLOps时代。
WhisperX – 具有单词级时间戳和分离的语音识别
你是否与OpenAI的开创性语音识别模型Whisper有过交集?它就像是一位多语言大师,擅长于进行诸如语音转录、时间戳标记、语音到文本的翻译和语音检测等各种任务,而且支持多种语言。
现在,让我向您介绍它的增强版——WhisperX。它就像是喝了一杯浓缩咖啡的Whisper,拥有更准确的时间戳、多个说话者检测,并通过增强语音活动检测来减少幻听(不是指迷幻效果,而是指在没有人说话时开始涌现词语的情况)。最棒的是,它在更快速和更节省内存的同时实现了所有这些功能。
WhisperX拥有一个秘密武器,称为语音活动检测预处理。它就像一个保镖,只允许包含语音活动的音频片段进入,而且比让每个人都参加完全自动语音识别派对要便宜得多。这种方法还确保音频被切割成整齐的块,避免了在演讲中间出现尴尬的切割,并提高了整个单词检测的可靠性。此外,时间戳也被整理得与这些边界相匹配,使它们更加准确。最后的一步是使用一个音素分类器模型,根据固定的、每种语言的字典来对齐单词边界。这就像在你的团队中有一个语法纠正者。
好奇看到它的实际效果吗?在他们的GitHub存储库上查看结果的英文示例。
WhisperX的美妙之处在于可以并行处理数据块,就像一个运转良好的装配线,从而实现批量推理。而且,由于切换到更快的Whisper后端,whisper-large模型的RAM使用量已经减少到不到8GB。这意味着它现在可以与更广泛的显卡兼容,并且在相同模型上的速度提升高达70倍。就像将你的语音识别放在高速跑步机上一样。
对于喜欢深入研究细节的好奇心,作者们慷慨地分享了他们的预印本论文。
8. AutoGen – LLM 会话协作套件
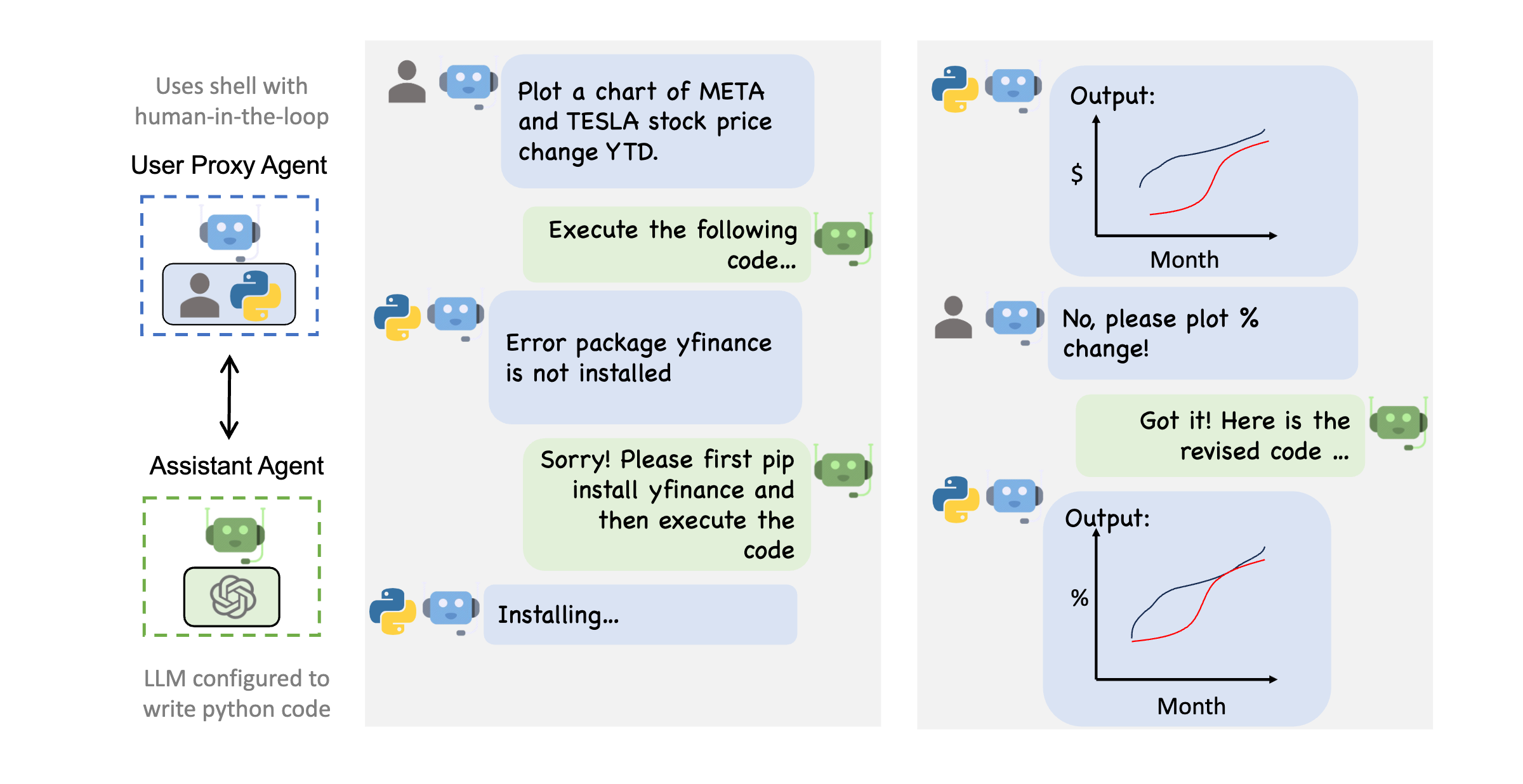
AutoGen:与人类干预的代理协作。来源:AutoGen多代理对话框架
曾经梦想过拥有一支个人软件工程团队,随时准备将您的应用创意变为现实吗?来见识一下微软的AutoGen吧,它就像是您的魔法棒,能够召唤出协同工作、共同实现目标的对话代理。就像复仇者联盟一样,但用于软件开发。
AutoGen的最简单的设置有两个关键角色: AssistantAgent 和 UserProxyAgent 。 AssistantAgent 是你的AI助手,旨在独立执行任务。与此同时, UserProxyAgent 是你的数字替身,允许你在需要人类干预时介入,同时也能代表你行动。就像你既能拥有蛋糕又能吃掉它一样!
AssistantAgent 执行任务,而 UserProxyAgent 向 AssistantAgent 提供任务是否成功完成的反馈。一旦任务设定好,这些代理就会自主行动,直到需要人类监督或成功完成任务为止。
这个框架在代码生成等使用场景中表现出色。 AssistantAgent 制作代码,而 UserProxyAgent 测试代码。如果出现错误, UserProxyAgent 提供反馈,循环重复。就像拥有一个个人的代码工厂。
AutoGen的美妙之处在于其可扩展性。您可以引入额外的代理来担任各种角色,就像建立您的软件开发团队一样。需要一个测试代理或产品经理?AutoGen可以满足您的需求。为了获得灵感,可以查看ChatDev,这是一个使用类似概念构建整个软件团队的项目。
AutoGen还拥有多个增强推理功能,为您的工作流程提供支持。它统一了多个模型的API,使您能够将多个LLMs链接到一个单一的代理后面:如果一个模型失败,下一个模型接替其位置,确保鲁棒性。此外,它提供了一个快速、经济高效的推理结果缓存,用于加速推理过程,还提供了聊天记录以进行调试,以及提示模板,可以在多个任务中重复使用常见指令(例如逐步解释您的推理过程)。
但这还不是全部。您想要使用RAG增强您的代理吗?只需将 Retrieve 添加到它们的类名中,并提供一个文档路径,就可以了!您的代理现在可以利用自定义数据库提供特定上下文的信息。想要一个能够边学边做的代理吗?尝试通过提示向TeachableAgent解释一些内容,它将把您提供的信息存储在一个MemGPT风格的嵌入式数据库中,以便在将来的交互中回忆和推理这个上下文。这个功能的一个非常强大的用途是让您的代理思考在它们的交互中起作用的内容,并生成一个步骤的摘要,然后教给TeachableAgent这个步骤,这样它就知道下次该如何做了。
为了总结一切,AutoGen提供了强大的安全措施。AutoGen团队强烈建议在Docker容器中运行您的代理代码。您知道的,以防万一您偶然发现了解锁AGI的代理组合。😉😉。有了AutoGen,天空的确是无限的。
9. Guardrails – 照看LLMs,使其按预期行为

你是否曾经遇到过一个非常棒的提示,经过精心设计的细致提示工程过程,但却发现你的大型语言模型突破了束缚,回答了一个非结构化的答案?或者一个LLM没有按照你的指示行事,提到了你的竞争对手?
LLMs的灵活性提供了广泛的应用范围,但也使其整合到更大的流程中变得具有挑战性。引入Guardrails:这是一个库,旨在指定结构和类型,并验证和纠正大型语言模型的输出。
护栏通过定义一种名为.rail规范的XML变体来工作,该规范旨在可读性强,允许定义所请求输出的结构,验证器以确保值符合给定的质量标准,并采取纠正措施,例如重新询问LLM或者在验证未通过时过滤掉无效的输出。
这是一个示例,它在 format 字段中指定了质量标准(生成长度、URL可达性),在 RAIL 规范中重新请求 explanation 并过滤掉无效的 follow_up_url 。
<rail version="0.1">
<output>
<object name="bank_run" format="length: 2">
<string
name="explanation"
description="A paragraph about what a bank run is."
format="length: 200 280"
on-fail-length="reask"
/>
<url
name="follow_up_url"
description="A web URL where I can read more about bank runs."
format="valid-url"
on-fail-valid-url="filter"
/>
</object>
</output>
<prompt>
Explain what a bank run is in a tweet.
${gr.xml_prefix_prompt}
${output_schema}
${gr.json_suffix_prompt_v2_wo_none}
</prompt>
</rail>
这些守卫可以从RailSpec或PyDantic类型定义进行初始化,甚至可以使用字符串来处理较简单的用例。然后可以使用该结构来定义LLM必须生成的字段及其类型,包括在逻辑中定义的嵌套对象。提供了多个验证器,从简单的字符串最小/最大长度或正则表达式验证到无语法错误的Python或SQL代码、无亵渎文字等等(更多信息请参见https://docs.guardrailsai.com/api_reference/validators/)。
有了Guardrails在你的堆栈中,你的LLM应用程序必定更加可靠和强大,这样更容易将它们集成到你的流程中。
10. Temporian – 为预处理时间数据而构建的“熊猫”

时间至关重要。时间就是金钱。时间不多了……你之前听过这些吧?时间数据在大多数人类活动中无处不在,这就是为什么许多流行的库允许表示和操作时间序列数据:一系列具有相等时间间隔的值。
然而,传统的时间序列方法在表示许多种不等间隔的现实世界时间数据方面存在不足,例如网站上的用户点击或零售商店中发生的销售。
在这种情况下,一直以来的常用方法是使用通用的数据预处理工具,比如pandas,通过重新采样和聚合将数据压缩成表格格式——在整个特征工程过程中失去了灵活性和细粒度。
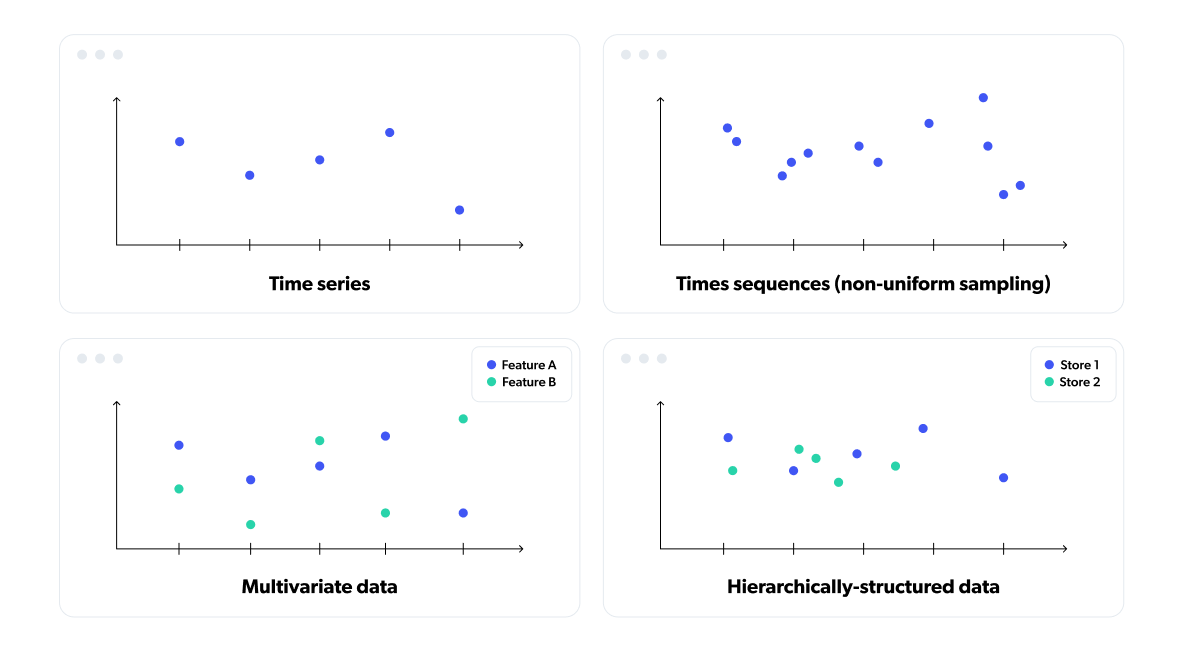
这就是为什么Tryolabs与Google合作开发了一款用于时间数据处理的先进库。Temporian通过Python API和C++实现的支持,实现了对时间数据的安全、简单和高效的预处理和特征工程。Temporian支持多变量时间序列、多变量时间序列、事件日志和跨源事件流。
Temporian的核心是 EventSet ,其中包含了被称为事件的时间戳记录,这些记录保存了特征值。 EventSets 可以包含具有均匀或非均匀时间戳的多变量时间序列,以及属于不同实体的独立序列。方便的操作符,如滞后、重新采样和窗口函数,有助于填补间隙并对时间戳进行对齐以进行算术运算。
为了了解API的功能,这里是一个简单的Temporian代码片段,它计算了销售数据集中每个商店的每日收入,采样时间为每个工作日的晚上10点
import temporian as tp
sales = tp.from_csv("sales.csv")
sales_per_store = sales.add_index("store")
days = sales_per_store.tick_calendar(hour=22)
work_days = (days.calendar_day_of_week() <= 5).filter()
daily_revenue = sales_per_store["revenue"].moving_sum(tp.duration.days(1), sampling=work_days)
Temporian提出了一种新的范式,用于处理时间数据。它专为此而设计,并且其核心计算以高度优化的C++代码运行,使得常见的时间操作更安全、更易于编写,并且执行速度大大提高——基准测试显示,与等效的pandas代码相比,速度提升可达100倍以上。
如果你好奇的话,请查看文档中的教程,它将通过使用该库的真实示例来引导你。当然,我们非常欢迎任何反馈 🙂
亚军
以下图书馆几乎进入了我们的首选名单,我们认为它们值得特别认可:
DataGradients – 为计算机视觉数据集分析提供个人助手。DataGradients是Deci AI的创意,是一个开源的Python库,提供了视觉数据集管理中常见任务的解决方案。无论是识别损坏的图像、错误的标签、偏见、提取摘要以深入了解可用数据,还是为超参数选择提供指导,DataGradients都能满足您的需求。
functime 是一个针对大型面板数据集的时间序列预测和特征提取的综合库。它提供了独特的预处理选项和交叉验证分割器。由于智能使用Polars进行并行特征工程,它以其令人难以置信的速度和效率脱颖而出,能够在几秒钟内处理10万个时间序列。但是,functime不仅仅是速度快,它还是一个强大的盟友,配备了经过验证的机器学习算法,并支持所有预测器的外生特征。它还是自动化的,使用FLAML来管理滞后和超参数调整。在其自定义命名空间中提供了超过100个时间序列特征提取器,functime提供了一个高效、用户友好的平台,改变了我们处理时间序列数据的方式。
LoRaX 是Predibase开发的推理服务器,可扩展到数千个经过精细调整的LLMs。LoRaX(“LoRA交换”)旨在在单个GPU上提供多种经过精细调整的模型,显著降低了与服务相关的成本,同时保持了令人印象深刻的吞吐量和延迟。主要功能包括动态适配器加载,可以实时加载任何经过精细调整的LoRA适配器,而不影响并发请求;异构连续批处理,将不同的适配器请求组合在一起,以保持稳定的延迟和吞吐量;以及适配器交换调度,高效地管理适配器的预取和GPU与CPU之间的卸载。它支持一系列大型语言模型,如Llama和Mistral作为基础模型,并且与使用PEFT和Ludwig库训练的LoRA适配器兼容。
outlines – 使用LLMs进行引导文本生成,特别关注受限文本生成。通过使用非常高效的正则表达式引导生成,允许模型引导,如多项选择、类型约束和动态停止,与其他引导方法相比,推理速度更快。100%的时间生成有效的JSON!请查看他们的HN发布博客文章以获取更多见解。
Pearl ——Meta的应用强化学习(RL)团队的礼物。它是一个可投入生产的AI代理库,优先考虑累积的长期回报而非即时反馈。这些代理可以适应具有有限可观测性、稀疏反馈和高随机性的环境,使其成为解决各种现实世界问题的合适选择。珍珠对最先进的RL算法进行了模块化实现,证明了其多功能性和前瞻性的方法。
PEFT(由Hugging Face提供)或称为参数高效微调方法,是您微调预训练语言模型以适用于各种下游应用的通行证,无需更改所有模型参数,节省计算资源的同时保留更通用模型的良好特性,并提高在特定任务上的性能。
vLLM是一个高吞吐量和内存高效的推理和服务引擎,用于LLMs。它提高了LLM的服务性能,比之前的最先进技术提升了3.5倍,而不改变模型架构。由于输出大小事先不知道,通常会预留非常大且浪费的连续内存块,大小与模型输出大小一样。这个秘密(实际上并不秘密,是开源的)的关键是一种名为PagedAttention的算法,它将LLMs使用的键值缓存物理上分割为固定长度的、短的和动态分配的块。动态分配可以防止内存浪费,使更多提示能够适应VRAM,从而实现更快的吞吐量。截至撰写本文时,vLLM已被许多大型企业采用作为服务解决方案,成为事实上的标准服务解决方案。
隐藏的宝藏:揭示2023年Python库的长尾部分
虽然我们的首选项目确实吸引了人们的注意,但还有一整套的Python库没有进入主舞台,但同样值得您关注。我们分析了超过120个创新的Python库,每个库都具有独特的功能和尖端特性,如果我们要公正地对待每一个库,我们将需要等到下一届冬季奥运会!
为了帮助您浏览这个宝库,我们已经将这些图书馆进行了整理分类,并将它们的关键特点提炼成简洁的一句总结。
因果推断
CausalTune-用于因果估计器的自动调整和选择的库。
CausalPy – 用于准实验环境中因果推断的Python包。
PyWhy-LLM — 实验性库,集成LLM功能以支持因果分析。
CLI LLM 工具
Chatblade – 在命令行上使用的ChatGPT,提供从ChatGPT响应中提取JSON或Markdown的实用方法。
Elia – 使用Textual构建的终端ChatGPT客户端。
Gorilla CLI ——为您的命令行交互提供用户中心的工具。只需说明您的目标,Gorilla CLI将生成可能的执行命令。
LLM — 一个用于与大型语言模型进行交互的命令行实用程序和Python库,可以通过远程API和安装在自己的机器上运行的模型进行交互。由Datasette的作者开发。
代码工具
Chainlit – “ChatGPT的Streamlit”,在任何Python代码上创建类似ChatGPT的用户界面,只需几分钟!
pydistcheck – 在Python软件包分发(wheels和sdists)中查找可移植性问题的代码检查工具。
pyxet – XetHub平台的轻量级接口,具有类似文件系统界面和git功能的blob存储。
计算机视觉
deepdoctection – 使用深度学习模型协调文档提取和文档布局分析任务。
FaceFusion – 下一代人脸交换和增强工具。
MetaSeg – 分割任何物体模型(SAM)的打包版本。
VTracer是一款开源软件,用于将光栅图像(如jpg和png)转换为矢量图形(svg)
数据和特点
Adala – Adala – 自主数据(标注)代理框架。
Autolabel – 使用LLMs标记、清洗和丰富文本数据集。
balance – 在从偏倚的数据样本中推断到感兴趣的目标人群时,采用简单的工作流程和方法。请参阅发布的博客文章。由META提供。
Bytewax 是一个简化事件和流处理的Python框架。由于Bytewax将Flink、Spark和Kafka Streams的流和事件处理能力与Python的友好和熟悉的界面相结合,您可以重复使用您已经熟悉和喜爱的Python库。
Featureform 特征形式 – 特征存储。将您现有的数据基础设施转化为特征存储。
Galactic 银河清洁和整理工具,用于大规模非结构化文本数据集。Ben在X上得分48/100。
Great Expectations – 通过质量测试、文档编写和数据分析,帮助数据团队建立对数据的共同理解。
数据可视化
PyGWalker – 将您的pandas DataFrame转换为Tableau风格的用户界面,用于可视化分析。
Vizro – 一个用于创建模块化数据可视化应用的工具包。由麦肯锡提供。
嵌入和向量数据库
Epsilla是一个高性能的向量数据库管理系统,专注于向量搜索的可扩展性、高性能和成本效益。
LanceDB是一个使用持久存储构建的用于向量搜索的开源数据库,它极大地简化了嵌入式的检索、过滤和管理。
SeaGOAT是一种利用向量嵌入技术的本地搜索工具,可以在代码库中进行语义搜索。
Text Embeddings Inference ——一个针对文本嵌入模型的高速推理解决方案。
联邦学习
Flower – 一个友好的联邦学习框架。
MetisFL 是一个联邦学习框架,允许开发者轻松地将他们的机器学习工作流联合起来,在分布式数据孤岛上训练模型,而无需将数据收集到集中位置。
生成式人工智能
AudioCraft – 用于音频处理和生成的深度学习库。由Meta开发。
Image Eval – 用于评估您喜爱的图像生成模型的工具包。LinkedIn发布帖。
imaginAIry – Pythonic生成stable diffusion图像。
Modular Diffusion – 用于设计和训练自己的PyTorch扩散模型的Python库。
SapientML – 面向表格数据的生成式自动机器学习。
LLM 精确度增强
AutoChain – AutoChain:构建轻量级、可扩展和可测试的LLM代理
Auto-GPT — 一个试图使GPT-4完全自主的实验性开源尝试。
Autotrain-Advanced-更快、更简便地训练和部署最先进的机器学习模型。
DSPy是一个用于解决语言模型(LMs)和检索模型(RMs)高级任务的框架。DSPy统一了用于提示和微调LMs的技术,以及用于推理和工具/检索增强的方法。由斯坦福大学自然语言处理实验室开发。
GPTCache是一个用于创建语义缓存以存储LLM查询响应的库。
Neural-Cherche – 在特定数据集上微调神经搜索模型,如Splade、ColBERT和SparseEmbed,并在经过微调的检索器或排序器上运行高效的推理。
MemGPT – 教授无限上下文的内存管理 📚🦙。
nanoGPT是训练/微调中等规模GPT模型的最简单、最快速的存储库。
Promptify – 适用于各种情况的常见提示,可以很好地利用LLMs。
SymbolicAI – 组合可微编程库。
zep – 一个用于LLM / Chatbot 应用的长期记忆存储。轻松地将相关文档、聊天历史记忆和丰富的用户数据添加到您的LLM 应用的提示中。
LLM 应用程序构建
autollm – 在几秒钟内发布基于RAG的LLM网络应用程序。
Chidoriv-用于构建AI代理的反应式运行时。它提供了一个框架,用于构建具有反应性、可观察性和稳健性的AI代理。它支持使用Node.js、Python和Rust构建代理。
FastChat是一个基于大型语言模型的聊天机器人的开放平台,用于培训、服务和评估。
GPTRouter – 平滑管理多个LLMs和图像模型,加快响应速度,确保不间断的可靠性。类似于LiteLLM,我们的首选!
guidance – 用于控制大型语言模型的指导语言。
haystack – 一种端到端的自然语言处理框架,可以帮助您构建由LLMs、Transformer模型、向量搜索等驱动的自然语言处理应用程序。
Instructor – 通过Python代码与OpenAI的函数调用API进行交互,使用Python的结构/对象。
Jsonformer – 从语言模型生成结构化JSON的可靠方法
Langroid – 轻松构建LLM驱动的应用程序。设置代理,为其配备可选组件(LLM,向量存储和方法),分配任务,并通过交换消息使它们协同解决问题。
LLM 应用程序 – 通过根据您的数据源中最新的知识提供实时人类般的响应,构建创新的人工智能应用程序。
maccarone – 在Python中由AI管理的代码块,允许您将Python程序的部分委托给AI所有权。
magentic 使用装饰器将LLMs作为简单的Python函数进行快速转换。
Semantic Kernel – 将最先进的LLM技术快速轻松地集成到您的应用程序中。微软的“版本”LangChain。
LLM 代码工具
aider是一个命令行工具,可以让你与GPT-3.5/GPT-4进行配对编程,以编辑存储在本地git仓库中的代码。
ChatGDB — 在GDB调试器中利用ChatGPT的强大功能!
Dataherald是一个为企业级结构化数据问题回答而构建的自然语言到SQL的引擎。HN发布帖子。
FauxPilot – 开源的GitHub Copilot服务器。
GPT工程师 – 指定您想要它构建的内容,AI会要求澄清,然后进行构建。
gpt-repository-loader是一个命令行工具,将Git仓库的内容转换为可以被LLMs解释的文本格式。
ipython-gpt是一个扩展,允许您直接从Jupyter Notebook或IPython Shell中使用ChatGPT。
Jupyter AI – JupyterLab的生成式人工智能扩展。
PlotAI – 使用ChatGPT在Python脚本或笔记本中直接创建Python和Matplotlib绘图。- sketch — AI code-writing assistant for pandas users that understands the context of your data, greatly improving the relevance of suggestions.
LLM 开发
distilabel — 可扩展的LLM对齐的AI反馈框架。
语言模型算术 – 通过语言模型算术进行受控文本生成。
Lit-GPT是基于nanoGPT的最新开源LLMs的可修改实现。支持闪存注意力、4位和8位量化、LoRA和LLaMA-Adapter微调以及预训练。
Lit-LLaMA – 基于nanoGPT的LLaMA语言模型的实现。支持闪存注意力、Int8和GPTQ 4位量化、LoRA和LLaMA-Adapter微调、预训练。
LMQL — 一种用于编程(大型)语言模型的查询语言。
LLM 实验
ChainForge是一个开源的可视化编程环境,用于对LLMs进行战斗测试。
Langflow – LangChain的用户界面,使用react-flow设计,提供了一种轻松的方式来实验和原型化流程。
PromptTools是一套开源的、可自托管的工具,用于实验、测试和评估LLMs、向量数据库和提示。HN发布帖子。
LLM 指标
DeepEval是一个简单易用的开源评估框架,用于LLM应用程序。
Fiddler Auditor-评估语言模型的稳健性的工具。
RAG(检索增强生成)管道的评估框架。
tvalmetrics-用于评估检索增强生成(RAG)应用程序响应质量的指标。
LLM 服务
Aviary – 一种方便部署和管理各种开源LLMs的LLM解决方案。由Ray的作者提供。
GPT4All是一个生态系统,可以在消费级CPU和任何GPU上运行强大且定制化的大型语言模型(例如pygpt4all/pyllamacpp),并提供Python绑定。
LLM Engine – 用于微调和提供大型语言模型的引擎。由Scale AI提供。
LLM Gateway – 与OpenAI和其他LLM提供商进行安全可靠通信的网关。
punica – 将多个经过细调的LLM作为一个服务。
Ollama – 使用Llama 2和其他大型语言模型在本地快速启动和运行。
OnPrem.LLM — 用于在本地运行大型语言模型并处理非公开数据的工具。
OpenLLM是一个用于在生产环境中操作大型语言模型的开放平台。轻松进行微调、提供、部署和监控任何模型。由BentoML提供。
OpenLLMetry – 基于OpenTelemetry的开源可观测性解决方案,适用于您的LLM应用程序。
privateGPT 使用GPT的强大功能,私密地与您的文档进行交互,100%私密,无数据泄漏。
LLM 工具
IncarnaMind – 在一分钟内通过GPT和ClaudeLLMs连接和聊天与您的多个文档(pdf和txt)。
Puncia – 利用人工智能和其他工具,它将告诉您有关网域或子域的所有信息,例如发现隐藏的子域。
scrapeghost – 使用OpenAI的GPT API进行网站爬取的实验性库。
MLOps,LLMOps,DevOps
phoenix – 笔记本中的机器学习可观察性 – 发现洞察力,揭示问题,监控和微调您的生成LLM,计算机视觉和表格模型。
多模态人工智能工具
LLaVAv — 视觉指导调整 – 大型语言和视觉助手,旨在实现多模态GPT-4级别的能力。- Multimodal-Maestro — effective prompting for Large Multimodal Models like GPT-4 Vision, LLaVA or CogVLM.
重试
错误原因
nougat – 一种能够理解LaTeX数学和表格的学术文档PDF解析器。
UForm – 口袋大小的多模态人工智能,用于语义搜索和推荐系统。
Python机器学习
difflogic – 一种由Felix Petersen开发的可微分逻辑门网络的库。
TensorDict – 一种类似字典的类,继承了张量的属性,如索引、形状操作、转换到设备等。TensorDict的主要目的是通过抽象定制操作,使代码更易读和模块化。
性能和可扩展性
AITemplate是一个Python框架,将神经网络渲染成高性能的CUDA/HIP C++代码。专门用于FP16 TensorCore(NVIDIA GPU)和MatrixCore(AMD GPU)推理。
AutoGPTQ是一个易于使用的LLMs量化包,具有用户友好的API,基于GPTQ算法。
composer – PyTorch库,可以让您以更快的速度、更低的成本和更高的准确性训练神经网络。实现了超过二十种加速方法,只需几行代码即可应用于您的训练循环。
fastLLaMa — 使用C++运行LLaMA模型推理的Python封装。
hidet是一个开源的深度学习编译器,用Python编写。它支持从PyTorch和ONNX到高效的cuda内核的端到端DNN模型编译。
LPython是一个编译器,它会对类型注解的Python代码进行积极优化。它有几个后端,包括LLVM、C、C++和WASM。LPython的主要原则是速度。发布博客文章。
花瓣 – 在家中运行100B+语言模型,类似BitTorrent的方式。微调和推理速度比外部处理快10倍。
TokenMonster – 在任何特定词汇量下,确定最佳地表示数据集的标记
Python编程
Django Ninja CRUD – 使用Django Ninja进行声明式CRUD端点和测试。
DotDict – 一个简单的Python库,使得链式属性成为可能。
grai-core – 数据血统简化。Grai使得您可以轻松理解和测试您的数据在数据库、数据仓库、API和仪表板之间的关系。HN发布博客文章。
pypipe – Python管道命令行工具。
ReactPy是一个用Python构建用户界面的库,无需使用Javascript,由类似于ReactJS中的组件构成。
Reflex – 用纯Python构建Web应用程序的开源框架。发布公告。
scrat – 缓存昂贵的函数结果,类似于lru_cache,但具有持久性到磁盘。
svcs – 一个用于Python SVCS的依赖容器
view.py – 高速、现代化的Web框架。目前处于非常早期的开发阶段。HN发布帖。
优化/数学
Lineax – 用于线性求解和线性最小二乘的JAX库。发布推文。
pyribs-一个用于质量多样性优化的简化版Python库。
强化学习
cheese – 语言和嵌入模型的自适应人机交互评估。
imitation – 清洁的PyTorch实现模仿和奖励学习算法。
RL4LMs是一个模块化的强化学习库,用于根据人类偏好对语言模型进行微调。由AI2开发。
trlX – 通过人类反馈的强化学习实现语言模型的分布式训练。
时间序列
aeon – 一个用于时间序列机器学习的统一框架。
视频处理
VapourSynth – 以简洁为目标的视频处理框架。Python文档。