

介绍
大型语言模型是人工智能领域进步的支柱。随着各种开源大型语言模型的发布,对于特定于聊天机器人的用例的需求也越来越大。HuggingFace是开源大型语言模型的主要提供者,模型参数对公众开放,任何人都可以用于推理。另一方面,Langchain是一个强大的大型语言模型框架,可以帮助将人工智能无缝集成到您的应用程序中。通过结合Langchain和HuggingFace,可以轻松地整合特定领域的聊天机器人。
学习目标
了解开源大型语言模型的需求以及HuggingFace是最重要的提供者之一。
使用Langchain框架和HuggingFace开源模型来实现大型语言模型的三种方法。
学习如何使用T4 GPU免费在Langchain上实现HuggingFace任务流程。
学习如何使用Inference API在CPU上实现HuggingFace Hub中的模型,无需下载模型参数。
使用gguf格式实现LlamaCPP。大型语言模型格式。
本文是作为数据科学博客马拉松的一部分发表的。
目录

HuggingFace是开发人工智能和深度学习模型的基石。HuggingFace在Transformers存储库中拥有大量的开源模型,使其成为许多从业者的首选。公开可访问的学习参数是开源大型语言模型(如LLaMA、Falcon、Mistral等)的特点。相比之下,闭源大型语言模型具有私有的学习参数。使用这些模型可能需要与API端点进行交互,例如GPT-4和GPT-3.5。
这就是HuggingFace派上用场的地方。HuggingFace提供了HuggingFace Hub,这是一个拥有超过12万个模型、2万个数据集和5万个空间(演示人工智能应用程序)的平台。
什么是Langchain?
随着人工智能中大型语言模型的进步,对信息丰富的聊天机器人的需求很高。假设你创办了一家新的游戏公司,有许多用户手册和快捷文档。你需要将像ChatGPT这样的聊天机器人集成到这家公司的数据中。我们如何实现这一目标?
这就是Langchain的用武之地。Langchain是一个强大的大型语言模型框架,集成了各种组件,如嵌入、向量数据库、LLMs等。利用这些组件,我们可以将外部文档提供给重要的语言模型,并无缝地构建人工智能应用程序。
安装
我们需要安装所需的库,以便开始使用HuggingFace在Langchain上的不同方式。
要使用Langchain组件,我们可以直接使用以下命令安装Langchain
!pip install langchain
使用HuggingFace模型和嵌入,我们需要安装transformers和sentence transformers。在Google Colab的最新更新中,您无需安装transformers。
!pip install transformers
!pip install sentence-transformers
!pip install bitsandbytes accelerate
为了在边缘上运行GenAI应用程序,Georgi Gerganov开发了LLamaCPP。LLamaCPP使用高效的C/C++实现了Meta的LLaMa架构。
!pip install llama-cpp-python
方法一:HuggingFace管道
管道是使用模型进行推理的一种很好且简单的方式。HuggingFace提供了一个管道包装类,可以在一行代码中轻松集成文本生成和摘要等任务。这行代码包含通过实例化模型、分词器和任务名称来调用管道属性。
我们必须加载大型语言模型和相关的分词器来实现这一点。由于不是每个人都能访问A100或V100 GPU,我们必须使用免费的T4 GPU进行操作。为了使用管道运行大型语言模型进行推理,我们将使用orca-mini 30亿参数的LLM,并使用量化配置来减小模型大小。
from langchain.llms.huggingface_pipeline import HuggingFacePipeline
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline,
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
在提供的代码片段中,我们使用AutoModelForCausalLM来加载模型,使用AutoTokenizer来加载分词器。一旦模型和分词器加载完成,将模型和分词器分配给管道,并指定任务为文本生成。管道还允许通过修改max_new_tokens来调整输出序列的长度。
model_id = "pankajmathur/orca_mini_3b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=nf4_config
)
pipe = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512
)
成功运行管道,做得很好。HuggingFacePipeline包装类有助于集成Transformers模型和Langchain。下面的代码片段定义了orca模型的提示模板。
hf = HuggingFacePipeline(pipeline=pipe)
query = "Who is Shah Rukh Khan?"
prompt = f"""
### System:
You are an AI assistant that follows instruction extremely well.
Help as much as you can. Please be truthful and give direct answers
### User:
{query}
### Response:
"""
response = hf.predict(prompt)
print(response)
方法2:使用Inference API的HuggingFace Hub
在第一种方法中,您可能已经注意到,在使用管道时,模型和分词会下载和加载权重。如果模型的长度很大,这种方法可能会耗费很多时间。因此,HuggingFace Hub推理API非常方便。要将HuggingFace Hub与Langchain集成,需要一个HuggingFace访问令牌。
获取HuggingFace访问令牌的步骤
登录到HuggingFace.co。- Click on your profile icon at the top-right corner, then choose “Settings.”
在左侧边栏中,导航到“访问令牌”。
生成一个新的访问令牌,并将其分配给“写入”角色。
from langchain.llms import HuggingFaceHub
import os
from getpass import getpass
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass("HF Token:")
一旦获得访问令牌,使用HuggingFaceHub将Transformers模型与Langchain集成。在这种情况下,我们使用Zephyr,这是在Mistral 7B上微调的模型。
llm = HuggingFaceHub(
repo_id="huggingfaceh4/zephyr-7b-alpha",
model_kwargs={"temperature": 0.5, "max_length": 64,"max_new_tokens":512}
)
query = "What is capital of India and UAE?"
prompt = f"""
<|system|>
You are an AI assistant that follows instruction extremely well.
Please be truthful and give direct answers
</s>
<|user|>
{query}
</s>
<|assistant|>
"""
response = llm.predict(prompt)
print(response)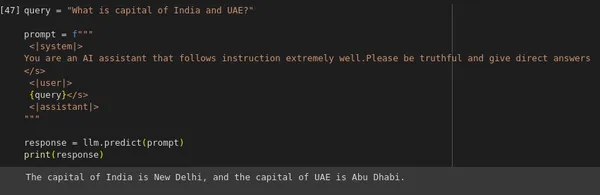
由于我们使用的是免费推理API,因此在使用13B、34B和70B模型的较大语言模型时存在一些限制。
方法三:LlamaCPP
LLamaCPP允许使用以.gguf文件格式打包的模型,在仅使用CPU和混合CPU/GPU环境中高效运行。
使用LlamaCPP,我们需要的模型必须以gguf结尾的model_path。您可以从这里下载模型:zephyr-7b-beta.Q4.gguf。一旦下载了这个模型,您可以直接将其上传到您的驱动器或任何其他本地存储设备。
from langchain.llms import LlamaCpp
from google.colab import drive
drive.mount('/content/drive')
llm_cpp = LlamaCpp(
streaming = True,
model_path="/content/drive/MyDrive/LLM_Model/zephyr-7b-beta.Q4_K_M.gguf",
n_gpu_layers=2,
n_batch=512,
temperature=0.75,
top_p=1,
verbose=True,
n_ctx=4096
)
由于我们使用的是Zephyr模型,提示模板保持不变。
query = "Who is Elon Musk?"
prompt = f"""
<|system|>
You are an AI assistant that follows instruction extremely well.
Please be truthful and give direct answers
</s>
<|user|>
{query}
</s>
<|assistant|>
"""
response = llm_cpp.predict(prompt)
print(response)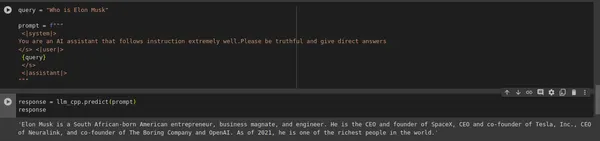
结论
总之,我们成功地将HuggingFace开源模型与Langchain结合使用。通过使用这些方法,人们可以轻松避免支付OpenAI API积分。本指南主要关注使用开源LLMs,这是RAG管道的一个重要组成部分。
主要要点
使用HuggingFace的Transformers管道,可以轻松选择任何性能优秀的大型语言模型,如Llama2 70B、Falcon 180B或Mistral 7B。推理脚本不超过五行代码。
由于不是所有人都能负担得起使用A100或V100 GPU,HuggingFace提供了免费的推理API(访问令牌),以实现从HuggingFace Hub中选择的一些模型。在这种情况下,最受欢迎的模型是7B模型。
当您需要在CPU上运行大型语言模型时,可以使用LLamaCPP。目前,LLamaCPP仅支持gguf模型文件。
建议按照提示模板在用户查询上运行predict()方法。
参考
- https://python.langchain.com/docs/integrations/llms/huggingface_hub
- https://python.langchain.com/docs/integrations/llms/huggingface_pipelines
- https://python.langchain.com/docs/integrations/llms/llamacpp
常见问题
如何在LangChain中使用Hugging Face模型?
有几种方法可以在Langchain中利用transformers的开源模型。首先,您可以使用HuggingFacePipelines的Transformers Pipeline。此外,您还可以选择使用HuggingFaceHub,以获得免费的推理和LlamaCPP。另外,还有一种可选的方法是使用HuggingFaceInferenceEndpoint,但这是需要付费的。
Q2. Hugging Face LLM是免费的吗?
是的,HuggingFace上的大型语言模型是开源且可访问的。它们可以通过Transformers框架进行访问。然而,如果您需要在HuggingFace云上托管您的语言模型,您需要根据您选择的InferenceEndpoint按小时付费。
Q3. 什么型号与LangChain兼容?
LangChain是一个强大的LLM框架,广泛用于检索增强生成。LangChain与各种大型语言模型兼容,如GPT 4,Transformers开源模型(LLama2,Zephyr,Mistral,Falcon),PaLM,Anyscale和Cohere。
LangChain和Hugging Face之间有什么区别?
LangChain是一个支持各种组件的大型语言模型,其中LLMs是其中之一。但它不存储或托管任何LLMs,而Transformers是一个核心深度学习框架,托管模型并提供空间来构建代码演示应用程序。