
本篇文章是对论文Bigtable-OSDI06的原创翻译,转载请严格遵守CC BY-NC-SA协议。
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach
Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber
{fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com
Google, Inc.
Bigtable是一个为管理大规模可伸缩的结构化数据而设计的的分布式存储系统,它可以跨上千台商用服务器管理PB级的数据。Google中很多项目将数据存储在Bigtable中,包括web索引、Google Earth和Google Finance。这些应用程序对Bigtable提出了非常不同的需求,这些不同包括数据大小不同(从URL到web页面再到卫星图像)和延迟要求不同(从后端批处理任务到实时数据服务)。尽管需求是多变的,Bigtable还是成功地为Google的所有这些产品提供了灵活的、高性能的解决方案。在本文中,我们描述了Bigtable提供的允许客户端动态控制数据布局和格式的简单数据模型,以及Bigtable的设计与实现。
在过去的两年半的时间里,我们在Google设计、实现并部署了一个用来管理结构化数据的分布式存储系统——Bigtable。Bigtable为可靠地适用于PB级数据和上千台机器而设计。Bigtable已经完成了几个目标:适用性广、可伸缩、高性能和高可用。Bigtable在超过60余个Google的产品和项目中被使用,包括Google Analytics、Google Finance、Orkut、个性化搜索、Writely和Google Earth。这些产品使用Bigtable以应对变化多样的负载需求,从吞吐量敏感的批处理程序到面相终端用户的延迟敏感的数据服务。这些产品使用的Bigtable集群配置也变化多样,从几台服务器到数千台服务器,最多的可以存储几百TB的数据。
Bigtable在很多方面都很像一个数据库:Bigtable和数据库的很多实现策略都是相同的。并行数据库[14]和内存数据库[13]已经做到了可伸缩和高性能,但是Bigtable提供了与这类系统不同的接口。Bigtable不支持完整的关系数据模型,取而代之的是,Bigtable提供了一个简单地数据模型,该模型允许客户端动态控制数据布局和格式,且允许客户端参与决策层数据在下层存储中的位置属性。数据通过可用任意字符串命名的行名和列名来索引。Bigtable将数据视为普通字符串且不关注其内容。客户端可以将不同格式的结构化或半结构化数据序列化为字符串。客户端可以小心地选择数据的schema来控制数据的位置。最后欧,Bigtable的schema参数允许客户端动态控制将数据放在内存中还是磁盘中使用。
第二章更详细地介绍了数据模型。第三章给出了客户端API的概览。第四章简要描述了Bigtable依赖的Google的下层基础设施。第五章描述了Bigtable的基本实现。第六章我们为Bigtable的性能做出的改进。第七章提供了Bigtable的性能测试。在第八章中,我们描述了一些关于Bigtable在Google中被如何使用的例子。在第九章中,我们讨论了我们在设计和支持Bigtable时认识到的一些问题。最后,第十章讨论了相关工作,第十一章给出了我们的结论。
Bigtable是一个稀疏的、分布式的、持久化的多维排序字典(map)。该字典通过行键(row key)、列键(column)和时间戳(timestamp)索引,字典中的每个值都是字节数组。
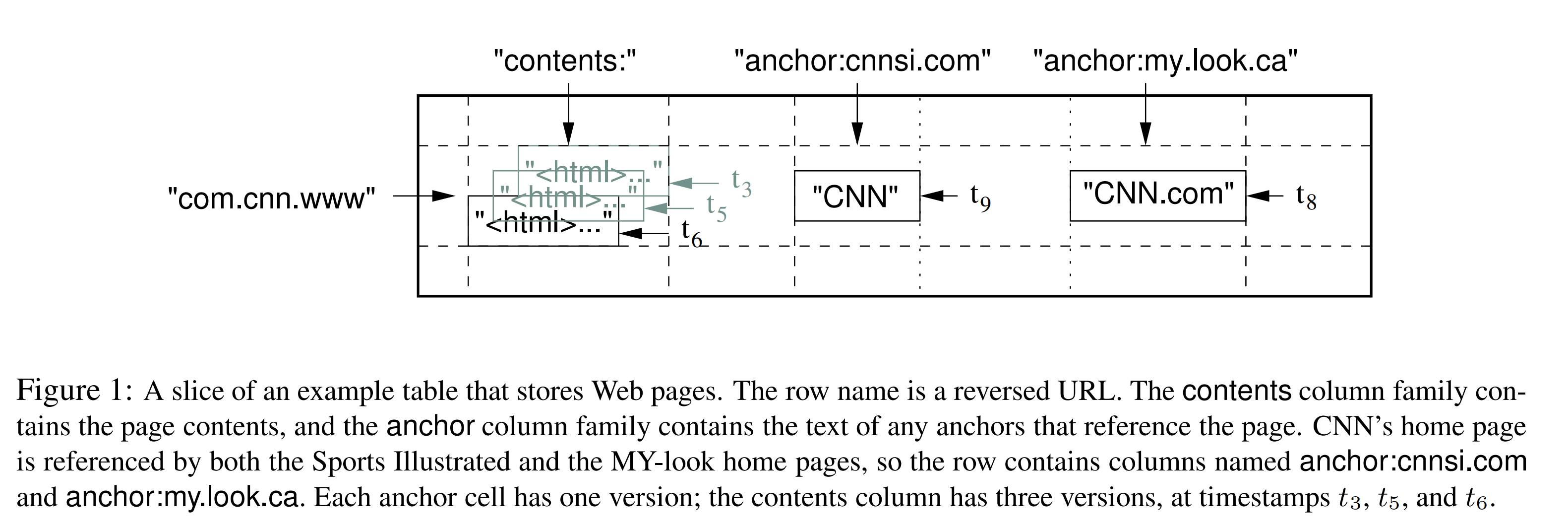
在调研了类Bigtable系统的各种潜在用途后,我们决定采用这种数据模型。驱动我们做出部分设计决策的案例是:假设我们想要持有一份可在很多项目中使用的大量web页面和相关信息的副本,我们称这个副本构成的特殊的表为Webtable。在Webtable中,我们使用URL作为行键,网页的不同性质作为列名,并将网页的内容和其被抓取的时间戳存储在“contentes:”列中,如图1中个所示。
{kind=link}
表中行键可以使任意的字符串(目前不能超过64KB,对大部分用户来说通常大小仅为10~100字节)。在单个行键下的读写是原子性的(无论该行中有多少不同的列正在被读写),这种设计决策使客户端对同一行并发更新时能够更容易地判断系统的行为。
Bigtable按照行键以字典序维护数据。表会对行区间动态分区。每个行区间被称为一个tablet,其为分布式和负载均衡的基本单位。这样做在读取较短的行区间时非常高效,且通常仅需要与较少的机器交互。客户端可以通过选择行键来利用这一性质,为数据访问提供更好的数据位置分布。例如,在Webtable中,通过将URL中hostname的各部分反转,可以将域名相同的网页被分组到连续的行中。如,我们会将“maps.google.com/index.thml”的数据使用键“com.google.maps/index。html”存储。将相同域名下的网页存储在相邻的位置可以使一些对主机和域名的分析更加高效。
列键被为一系列的组,这些组被称为“列族(column family)”,列族是访问控制(access control)的基本单位。被存储在同一列族下的数据通常为同一类型的(我们会将同一列族下的数据压缩在一起)。列族必须在数据被存储到该列族中任何列键下之前创建;在列族创建好后,该列族下任何列键都可以使用。我们希望减少表中不同列族的数量(最多在几百以内),且列族在操作期间很少被改变。相反,一个表中可以有无限多的列。
列键使用如下的格式命名:列族名:限定符。列族名必须是可打印(printable)的,但限定符可以是任何字符串。Webtable中的一个列族样例名为“language”。在“language”列族下仅使用了一个列键,在列键下存储的是网页的语言ID。该表中另一个很有用的列族为“anchor”。该列族下每个列键都表示一个单独的锚点(译注:若有一个网页引用了该网页,那么引用该网页的网站域名即为该网页的锚点),如图1所示。该列族中列键的限定符以引用该网页的网站名来命名,单元格的内容是该锚点的链接。
访问控制以及磁盘和内存统计都在列族级别执行。在我们的Webtable例子中,这些控制让我们能够对不同类型的应用程序做出不同的管理:有些应用程序被允许新增基本数据,有些应用程序被允许读取基本数据并创建派生的列族,有些应用程序仅被允许查看以后数据(且很有可能为隐私考虑无法阅读所有的列族)。
Bigtable中的单元格可以包含相同数据的不同版本,这些版本使用时间戳索引。Bigtable的时间戳是64位整型。时间戳可以被Bigtable分配,这样其可以以毫秒来表示当前时间;时间戳还可以通过客户端程序指定。如果应用程序需要避免时间戳碰撞,那么其必须自己生成唯一的时间戳。单元格的不同版本会按照时间戳倒序存储,这样最新的版本可以被最早读取。
为了使管理不同版本的数据更加简便,每个列族支持两种设置。通过设置可以使Bigtable能够自动地对单元格的版本进行垃圾回收。客户端可以指定Bigtable仅保留单元格的最后个版本,或者仅保留足够新的版本(例如,仅保留最近七天内写入的值)。
在我们的Webtable例子中,我们为“content:”列中存储的爬取到的页面设置的时间戳为:该版本的页面被爬取到的实际时间。上文中描述的垃圾回收机制允许我们仅保留每个页面的最近3个版本。
Bigtable的API提供了用于创建、删除表和列族的函数。还提供了修改集群、表和列族的元数据(如访问控制权限)的函数。
客户端程序可以写入或删除Bigtable中的值、从个别行中查找值或者遍历表的子集中的数据。图2展示了在c++代码中使用RowMutation抽象来执行一系列更新。(省略了不相关的细节以保证示例简洁。)Apply调用会对Webtable执行一个原子性的变更:向“www.cnn.com”中增加一个anchor并删除另一个anchor。
{kind=link}
图3展示了在c++代码中使用Scanner抽象遍历特定行的所有anchor。客户端可以遍历多个列族。客户端有几种限制扫描获取的行、列和时间戳的机制。例如,我们可以限制扫描仅获取列名匹配正则表达式anchor:*.cnn.com的anchor,或者仅匹配时间戳在当前时间的十天内的anchor。
{kind=link}
Bigtable支持其他的一些允许用户通过更复杂的方式操作数据的特性。第一,Bigtable支持单行事务(single-row transaction),该特性可用作原子性地对一个行键下的数据串行地读、改、写。尽管Bigtable的客户端提供了跨行键的批量写入的接口,但是Bigtable目前不支持跨行键的事务。第二,Bigtable允许单元格被用作整型计数器。最后,Bigtable支持服务器的地址空间中执行用户提供的脚本。这些脚本通过Google开发的用于数据处理的Sawzall语言[28]编写。目前,基于Sawzall的API不允许客户端脚本将数据写回Bigtable,但支持多种形式的数据转换、基于任意表达式的数据过滤、使用多种操作符运算。
Bigtable可在MapReduce[12]中使用。MapReduce是一个Google开发的运行大规模并行计算的框架。我们已经编写了一系列的封装,来使Bigtable可以作为MapReduce任务的输入或输出。
Bigtable构建一些Google的其他基础架构之上。Bigtable使用了分布式的Google File System(GFS)[17]来存储日志和数据文件。Bigtable集群通常在运行着各式各样的分布式程序的共享的主机池上运行,且Bigtable进程经常与其他程序的进程在同一机器上运行。Bigtable依赖集群管理系统来调度任务、管理共享机器的资源、处理机器故障和监控机器状态。
我们内部使用Google SSTable文件格式来存储Bigtable的数据。SSTable提供了持久化的、按照键-值的顺序排序的不可变字典,其键值可以使任意的字节型字符串。SSTable提供了按照指定的键查找值和在指定键的范围内遍历键值对的操作。每个SSTable内部都包含一个块(block)的序列(块大小可通过配置修改,通常为64KB)。SSTable通过块索引(block index,存储在SSTable的结尾)来定位块,当SSTable被打开时,块索引会被载入到内存中。查找可通过一次磁盘seek操作实现:首先对内存中的块索引使用二分查找来查找指定块的位置,接着从磁盘读取该块。SSTable还可以可选地被完全映射的内存,这可以使查找和扫描不需要访问磁盘。
Bigtable依赖高可用、持久化的锁——[8]。一个Chubby服务包含5个活动的副本,这些副本中的一份被选举为master并处理请求。当这些副本中的大部分副本可以相互通信时,该服务即为可用的。Chubby使用Paxos算法[9, 23]维护副本一致性,以应对故障情况。Chubby提供了由目录和小文件组成的命名空间机制。每个目录或文件都可以用作锁,对文件的读写都是原子性的。Chubby的client库提供了对Chubby文件的一致性缓存。如果client在租约过期时间内没能更新session的租约,那么该session会过期。当session过期时,client会失去所有的锁和已经打开的句柄(handle)。Chubby的client还可以对Chubby的文件和目录注册回调(callback),当其被修改或session过期时会通知client。
Bigtable在很多任务中使用了Chubby,如:确保忍一时客服最多只有一个活动的master、存储Bigtable数据引导(bootstrap)位置(章节5.1)、发现tablet服务器并认定tablet服务器挂掉(章节5.2)、存储Bigtable的schema信息(每张表的列族信息)、存储访问控制列表。如果Chubby在较长的一段时间内不可用,那么Bigtable也会变得不可用。我们最近测量了跨11个Chubby实例的14个Bigtable集群中的效果。其中,由于Chubby(因Chubby停机或网络问题导致)不可用而导致的某些Bigtable中的数据不可用的时间平均占0.0047%。单个集群因Chubby不可用受影响占比为0.0326。
Bigtable的实现包含了三个主要的组件:链接到每个client中的库、一个master server、若干tablet server。tablet server可随着负载的变化动态被添加或删除到集群。
master负责将tablet分配到tablet server、检测tablet server的加入或过期、均衡tablet server的负载、回收GFS中的文件。除此之外,master还处理shcema变化,如表和列族的创建。
每个tablet server都管理一系列的tablet(通常每个tablet server管理大概十到一千个tablet)。tablet server处理对其加载的tablet读写请求,并在tablet增长得过大时分割tablet。
与其他单master的分布式存储系统[17, 21]类似,client的数据不直接发送到master,而是由client直接与tablet server通信来读写数据。因为Bigtable的client不依赖master查找tablet的位置信息,大部分的client从不与master通信。这样,master在实际环境中的负载非常低。
Bigtable集群可以存储大量的表。每个表都由一系列tablet组成。当表增长时会被自动分割成多个tablet,每个tablet默认大小约为100~200MB。
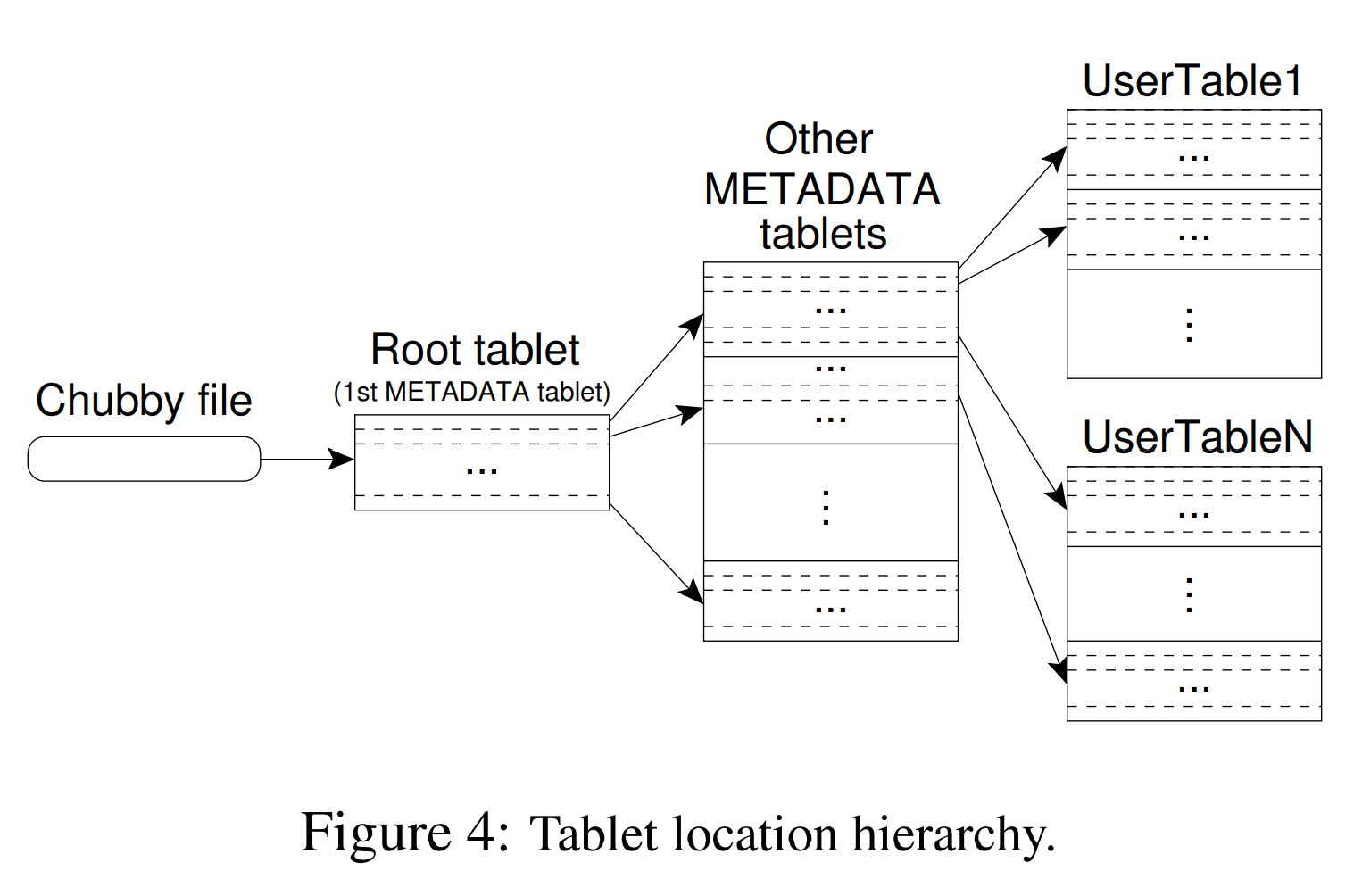
我们采用类似B+树[10]的三层的数据结构存储tablet位置信息(如图4所示)。
{kind=link}
第一层是一个存储在Chubby中的文件,其包含了root tablet的位置信息。root tablet中特殊的METADATA表包含了所有tablet的位置信息。每个METADATA tablet包含了一系列用户tablet的位置信息。虽然root tablet只是METADATA表的第一个tablet,但其被处理的方式比较特殊:root tablet永远不会被分割,这样可以保证tablet位置层级不超过三层。
METADATA表在一个行键下存储一个tablet的位置信息,该行键由这个tablet的标识符和其末行编码而得。METADATA表中每行在内存中大约占1KB。METADATA表大小限制为128MB,该三层位置信息结构能够提供个tablet的寻址能力。
client库会缓存tablet位置信息。如果client不知道tablet的位置或者其发现缓存的位置信息不正确,其会递归地向上查询。如果client的缓存为空,那么位置算法需要3轮网络交互,其中包括一次从Chubby中读取数据的网络交互。如果client的缓存数据较旧,那么其需要最多6轮网络交互,因为陈旧的缓存条目仅在失配时才会被发现(假设METADATA tablet不会频繁移动)。尽管因tablet位置信息被存储在内存中而不需要访问GFS,我们还是通过令client的库预拉取tablet位置信息的方式进一步削减了大多数场景下的开销。当client的读取METADATA表时,其会读取不止1个tablet的元数据。
我们还在METADATA表中存储了次要的信息,包括每个tablet的相关事件(如服务器为其提供服务的时间等)。这些信息对调试和性能分析非常有帮助。
每个tablet在同一时刻仅会被分配到一个tablet server。master会持续记录存活的tablet server和该tablet server中当前的tablet分配情况。当一个tablet未被分配且有空间足以容纳该tablet的tablet server可用时,master会通过向该tablet server发送一个tablet装载请求来分配tablet。
Bigtable使用Chubby来跟踪记录tablet server。当tablet server启动时,其会在指定Chubby目录下创建一个唯一命名的文件,并在该文件上获取排他锁。master监控这个目录(服务器目录)来发现tablet server。如果tablet server失去了其排他锁(例如因网络分区导致服务器失去了其访问Chubby的session),该tablet server会停止提供其tablet的服务。(Chubby提供了一个高效的机制使tablet server能够检查其是否仍持有持有锁且不会导致网络拥堵。)只要tablet server创建的文件还存在,tablet server就会试图新获取其文件的排他锁。如果这个文件不再存在,那么tablet server永远不会再次提供服务,因此其会杀死自己的进程。当一个tablet server终止时(例如由于集群管理系统将该tablet server所在的机器移出了集群),其会试图释放它持有的锁,这样master可以更快地重新分配tablet。
master需要检测到tablet server不再对其tablet提供服务的情况,并尽快地重新分配那些tablet。为了检测tablet server不再对其tablet提供服务的情况,master会间歇地询问每个tablet server的锁的状态。如果tablet server报告其失去了它的锁或者master在几次重试后仍无法访问tablet server,那么master会试图在该tablet server创建的文件上获取排他锁。如果master能够获取到锁,那么说明Chubby存活且tablet server可能挂掉或无法访问Chubby,master会删除该tablet server的文件以确保该tablet server永远无法再次提供服务。一旦tablet server创建的文件被删除,master便可以将之前分配到该tablet server上的tablet转变为一系列未分配的tablet。为了确保Bigtable集群在master和Chubby间网络出现问题的情况下的健壮性,master会在其Chubby session过期时杀死自己的进程。然而,如上文所述,master故障不会改变tablet在tablet server中的分配情况。
当master被集群管理系统启动时,它需要在对tablet的分配进行修改前发现当前tablet的分配情况。master会在启动时执行以下步骤:(1)master在Chubby中取得一个唯一的master锁以防止并发的master实例化。(2)master扫描Chubby中tablet server目录来寻找存活的tablet server。(3)master与每个存活的tablet server通信来发现每个tablet server中已分配的tablet情况。(4)master扫描METADATA表以了解tablet的状态。一旦扫描时遇到了未分配的tablet,master会将其加入到未分配的tablet的集合,使其符合tablet分配的条件。
这样,只有当METADATA的tablet被分配完成后才能扫描METADATA表。因此,在扫描开始前(步骤(4)),如果master在步骤(3)中没有找到root tablet的分配情况,master先将root tablet加入到未分配的tablet的集合中。这保证了root tablet会被分配。因为root tablet包含所有METADATA的tablet的名称,master会在扫描root tablet后获取到所有METADATA的tablet的信息。
已存在的tablet集合仅当有tablet被创建或删除、两个已存在的tablet合并为一个更大的tablet、或一个已存在的tablet被分割为来两个小tablet时被修改。除了最后一种修改,其他均由master启动,因此master可以追踪这些修改。而由于tablet的分割是由tablet server启动的,因此其处理方式不同。tablet server通过在METADATA表中记录新的tablet的信息的方式提交tablet分割。当分割被提交后,其会通知master。如果分割通知丢失(可能因tablet server或master挂掉造成),master会在其要求tablet server加载已经被分割的tablet时检测到新的tablet。此时,tablet server会将tablet分割信息告知master,因为master在METADATA表中找到的tablet条目仅为该tablet中被要求加载的部分(译注:master无法在METADATA表中找到tablet被分割的新的部分)。
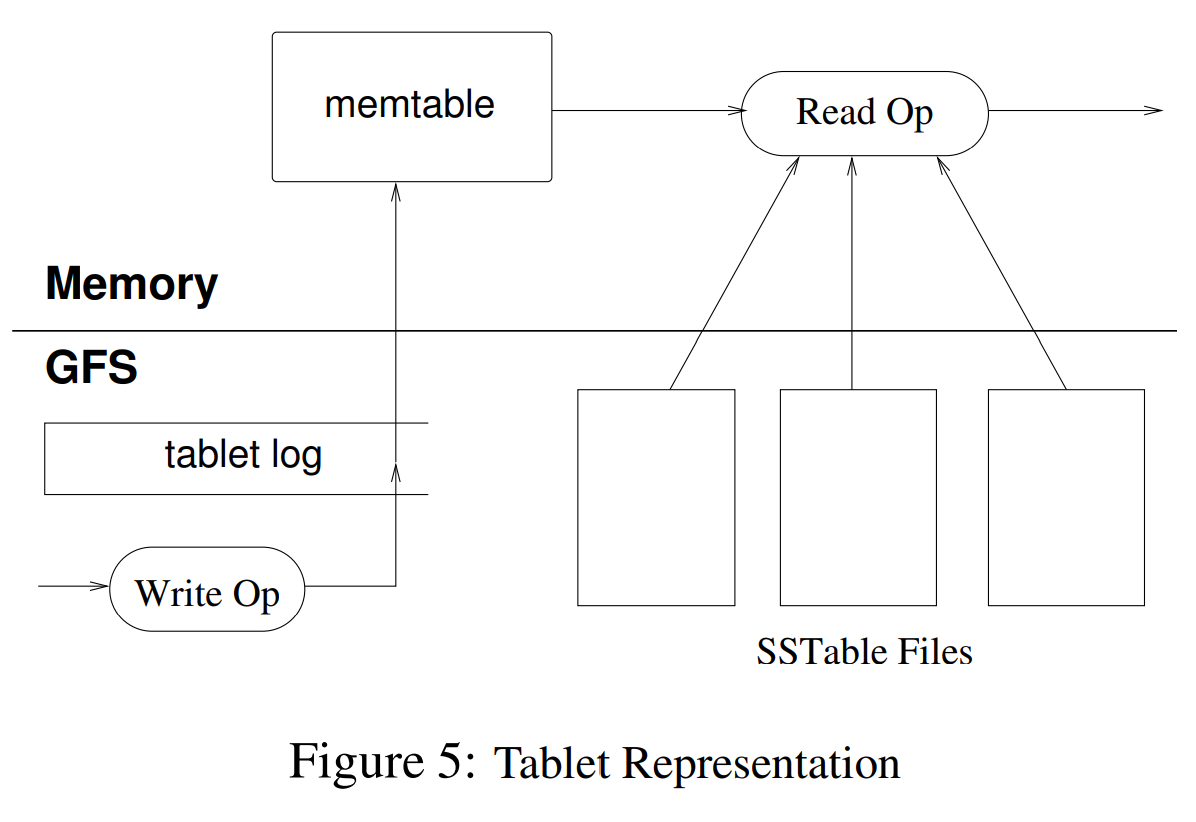
如图5所示,tablet的持久化状态被存储在GFS中。更新会被提交到存储着redo记录的commit log。其中,最近提交的更新会被存储在内存中被称为memtable的缓冲区中,较旧的更新会被存储在SSTable文件序列中。为了恢复一个tablet,tablet server会从METADATA表中读取其元数据。元数据包含了由tablet和一系列redo point(指向任何可能包括该tablet数据的指针)组成的SSTable列表。tablet server会将SSTable的索引读入内存,并通过应用所有redo point后的更新的方式重建memtable。
{kind=link}
当写操作到达tablet server时,tablet server会检查其是否格式正确且其sender是否被授权执行该变更。鉴权通过从一个Chubby文件(大多数情况下总是会命中Chubby client的缓存)中读取被允许的writer列表来实现。合法的变更会被写入到commit log中。tablet server使用了分组提交的方式来提高多个小变更[13, 16]的吞吐量。在写入操作被提交后,其内容会被插入到memtable中。
当读操作到达tablet server时,同样会检查格式是否和权限是否正确。合法的读操作会在SSTable序列和memtable的合并的视图上执行。因为SSTable和memtable是按照字典序排序的数据结构,所以可以高效地生成合并视图。
在tablet分割或合并时,到达的读写操作仍可继续执行。
执行写操作时,memtable的大小会增加。当memtable的大小达到临界值时,该memtable会被冻结,并创建一个新的memtable,被冻结的memtable会被转换成一个SSTable并写入到GFS中。该minor compaction进程有两个目标:其会较小tablet server的内存占用,并减小当server挂掉后恢复时需要读取的commit log的总数据量。当触发minor compaction时,到达的读写操作可以继续执行。
每次minor compaction会创建一个新的SSTable。如果该行为不受约束地持续执行,读操作可能需要合并来自任意数量的SSTable中的数据更新以获取数据。因此,通过间歇性地在后台执行merging compaction以限制这种文件的数量。merging compaction时会读取一些SSTable和memtable中的内容,并将其写入到一个新的SSTable中。一旦mergin compaction完成后即可丢弃输入的SSTable和memtable。
将所有的SSTable写入到恰好一个SSTable中的merging compaction被称为major compaction。非major compaction生产的SSTable可能包含特殊的删除操作项,删除操作项用来阻止对被删除的但仍在活动的数据的操作。(译注:当删除的数据正在活动时,Bigtable不会立刻删除这些数据,而是写入这个删除操作项。这样,使用了这些待删除的数据的活动可以继续正常执行,而后续的活动无法再访问这些待删除的数据。)而major compaction则相反,其创建的SSTable中不包含删除操作的信息或被删除的数据。Bigtable会循环遍历其tablet并周期性地对它们执行major compaction。major compaction允许Bigtable回收被删除的数据占用的资源,并使Bigtable能够确保被删除的数据能够及时地从系统中移除,这对存储敏感型数据服务来说十分重要。
在上一章中描述的数显需要很多改进才能满足我们的用户需要的高性能、高可用、高可靠性。本章将更详细地讲述各部分实现的改进。
client可以将多个列族组合为一个局部组(locality group)。每个tablet中的每个局部组会生成一个独立的SSTable。通常,可以将不在一起访问的列族放到不同的局部组中,以提高读取效率。例如Webtable中的页面元数据(如语言和校验和)可以放在一个局部组中,页面的内容可以放在不同的局部组中。这样,想要读取元数据的应用程序就不需要读取所有页面内容了。
除此之外,还可以为每个局部组指定不同的调优参数。例如,局部组可被声明为“内存型(in-memory)”。仅内存的局部组的SSTable会被懒式加载到tablet server的内存中。一旦加载完成,对这种局部组中的列族的访问就不需要访问磁盘。这个特性对被频繁访问的小规模数据非常有用。我们的METADATA表的位置列族的内部就使用了这一特性。
client可以控制是否要压缩局部组的SSTable及使用哪种压缩格式。用户指定的压缩格式会被应用到SSTable的每个块(其大小可通过局部组调参控制)。尽管分别压缩每个block会损失一些空间,但是当我们需要读取一个SSTable的一小部分时不需要解压缩整个文件。许多client采用自定义的二次压缩(two-pass compression)策略。第一次压缩使用Bentley and McIlroy[6]算法,其会压缩跨大窗口的相同的长字符串。第二次压缩使用更快的压缩算法,在16KB的小窗口周查找重复的数据。两次压缩都非常快,在现在机器上,可以以100~200MB/s的速度编码,以400~1000MB/s的速度解码。
尽管我们在选择压缩算法时强调速度而不是空间的减少,这种二次压缩的策略实际表现还是出奇的好。例如,在Webtable中,我们使用这种压缩策略来存储网页的内容。在一次实验中,我们在一个局部组中存储了大量的文档。为了达到实验目的,我们限制仅对每个文档存储一个版本而不是所有可用的版本。通过这种策略压缩后仅占用原来的十分之一的空间。而通常使用的Gzip仅能将空间压缩到原来的三分之一到四分之一。对于HTML页面,二次压缩策略比Gzip的表现好很多,这归功于Webtable的行的布局:所有来自同一个主机的页面被就近存储。这使Bentley-McIlroy算法能够在同一主机下识别到大量的相同的模式。不只是Webtable,对很多应用程序来说,都可以通过挑选它们的行名的方式来使相似的数据聚堆,这样可以得到非常好的压缩比例。当我们在Bigtable中存储同一个值的多个版本时,压缩比例甚至会更好。
为了提高读取性能,tablet server使用了二级缓存。Scan Cache是高层缓存,其将SSTable接口返回的键值对缓存到tablet server的代码中。Block Cache是低层缓存,其缓存从GFS读取的SSTable的块。对于更倾向于反复读取相同数据的应用程序来说,Scan Cache的作用更大。对更倾向于读取其最近读取的位置附近数据的应用程序来说,Block Cache的作用更大(例如,顺序读取、某个局部组的热点行中对不同列的随机读取)。
正如章节5.3中描述的那样,读操作必须读取所有组成了tablet状态的SSTable。如果这些SSTable不在内存中,会造成大量的磁盘访问。为了减少磁盘访问,我们允许client为特定的局部组创建布隆过滤器(Bloom filter)[7]。布隆过滤器让我们能够询问SSTable是否可能包含指定行或列的数据。对特定的应用程序来说,在tablet server中仅使用少量内存来存储布隆过滤器即可大大减少读操作所需的磁盘寻道次数。使用布隆过滤器意味着大多数对不存在的行或列的查找不需要访问磁盘。
如果我们为每个tablet单独保存一个commit log,将会有大量的文件在GFS中并发写入。由于GFS服务器的下层存储系统实现方式,这些写入操作会导致大量的磁盘寻道次数以写入不同的物理上的日志文件。此外,因为局部组经常很小,为每个tablet分别存储日志文件会削弱分组提交的优化效果。为了解决这些问题,我们将对每个tablet server上的tablet的变更追加到同一个commit log中,同一个物理日志文件中包含了来自不同tablet的变更[18, 20]。
使用同一个日志文件在执行一般操作时能够提供大幅的性能提高,但是复杂化了恢复操作。当一个tablet server挂掉时,其提供服务的tablet将会被移动到很多其他的tablet server上,每个tablet server通常仅加载原tablet server中少量的tablet。为了恢复tablet的状态,新的tablet server需要重新应用原tablet server上该tablet的commit log中的变更。然而,这些tablet的变更在同一个物理日志文件中。恢复的其中一种方法是,每个tablet server读取完整的commit log并进应用其需要恢复的tablet的日志条目。然而,在这种策略下,如果100台机器中每台机器都分到了一个来自故障tablet server的tablet,那么日志文件将要被读取100次(每台tablet server一次)。
为了避免多次读取commit log,首先会对commit log中的条目按照的键排序。在排序的输出中,每个特定的tablet的变更条目是连续的,这样就可以通过一次寻道和随后的顺序读取来高效地读取日志。为了并行化排序过程,我们将日志文件划分为64MB的段,并将每个段在不同的tablet server上并行地排序。排序进程由master协调,并在tablet server表名其需要从某个commit log文件中恢复变更时启动。
在将commit log写入到GFS是会因很多种原因导致性能波动(例如,涉及写操作的GFS机器崩溃,或者到涉及写操作的特定三台GFS服务器的网络拥塞、或者负载过高)。为了笔辩变更受GFS峰值时延的影响,每个tablet server实际上有两个日志写入线程,每个线程写各自的日志文件,在同一时刻二者中仅有一个线程被激活使用。如果写入到活动的日志文件的性能表现较差,那么日志的写入会切换到另一个线程,且在commit log队列中的变更会被新激活的日志写入线程写入。日志条目包含一个序号,这使恢复进程可以忽略因切换线程而产生的重复的日志条目。
如果master将一个tablet从一个tablet server移动到了另一个tablet server,源tablet server首先会对该tablet应用一次minor compaction。该操作会通过减少tablet server中的commit log中未压缩状态的的总量来减少恢复时间。当minor compaction完成后,tablet server会停止对该tablet提供服务。在其实际卸载该tablet之前,tablet server还会再进行一次minor compaction(通常很快)来消除任何在执行第一次minor compaction时到来的操作造成的剩余的未压缩的状态。在第二次minor compaction完成后,tablet可以被另一台tablet server装载且不需要恢复任何的日志条目。
因为我们生成的SSTable是不变的,所以除了SSTable的缓存,Bigtable系统的各种其他部分都可以被简化。例如,在我们为读取SSTable而访问文件系统时,不需要做任何的同步。这样,行的并发控制可以被高效实现。唯一的会同时被读写操作访问的可变数据结构是memtable。为了减少读取memtable的竞态,我们使memtable的每一行都在写入时复制(copy-on-write),并允许读写操作并行执行。
因为SSTable是不可变的,永久移除已删除的数据问题被转化成了对过时的SSTable的垃圾回收问题。每个tablet的SSTable都被会注册到METADATA表中。master对METADATA表的root tablet中记录的SSTable集合中的过时的SSTable集合应用“标记-清除(mark-and-sweep)”算法[25]进行垃圾回收。
最后,SSTable的不可变性可以让我们快速分割tablet。我们让子tablet共享父tablet,而不是为每个子tablet生成新的tablet。
我们构建了一个有个tablet server的Bigtable集群来测量Bigtable的性能和伸缩性,其中N有多种取值。tablet server的配置采用了1GB内存,数据通过一个由每台有两块400G IDE硬盘的1786台机器组成的GFS单元写入。Bigtable的测试负载由个client机器产生。(我们使用了与tablet server数量相同的client以确保client不会成为瓶颈。)每台机器有两块双核2GHz皓龙处理器、足以支撑所有的工作进程负载的物理内存、和一个1Gbps的以太网连接。这些机器被安排在二层树状交换机网络中,根节点总带宽约100~200Gbps。所有机器都在同一个托管设施中,因此任意一对机器间RTT时间小于1ms。
所有tablet server、master、测试client、GFS server都在同一组机器上运行。每台机器上都运行着一个GFS server。一些机器还运行着一个tablet server、或一个client进程、或与这些实验的同时运行的其他任务的进程。
在测试中,Bigtable使用了个不同的行键。选取的目的是使每个benchmark都会对每个tablet server读或写约1GB的数据。
顺序写入的benchmark使用了被命名为~的行键。行键的空间被拆分为了10N个大小相同的区间。这些区间被中心调度器分配给了N个client,当client完成对一个区间的处理后,该调度器会将下一个可用的区间分配给该client。这种动态分配的策略能够帮助减少在client机器上运行的其他进程造成的性能变化的影响。我们在每个行键下写入了一个字符串。每个字符串都是随机生成的,因此无法被压缩。另外,不同行键下的字符串是不同的,因此也无法跨行压缩。随机写入的benchmark与顺序写入的benchmark类似,除了行键在写入前采用了对取模的哈希算法,因此在整个benchmark期间,写入负载能够大致均匀地分布到整个行空间中。
顺序读取的benchmark生成行键的方法与顺序写入benchmark中的方法完全一致,但其在(在之前的顺序写入benchmark中已经生成好的)行键下读取而不是写入。与顺序读取benchmark相似,随机读取的benchmark也隐藏了随机写入benchmark中的操作。
扫描(scan)的benchmark与顺序读取的benchmark类似,但是其使用了Bigtable提供支持的API来扫描一个行键区间下的所有值。使用扫描的方式可以减少benchmark执行的RPC的数量,因为一个RPC即可获取tablet server中大量连续的值。
内存式随机读取的benchmark与随机读取的benchmark类似,但是去包含benchmark数据的局部组被标记为“内存型”。因此,读取由tablet server的内存满足,而不需要读取GFS。对于内存式读取的benchmark,我们将每个tabler的数据量从1GB减少到了100MB,以适配tablet server的内存大小。
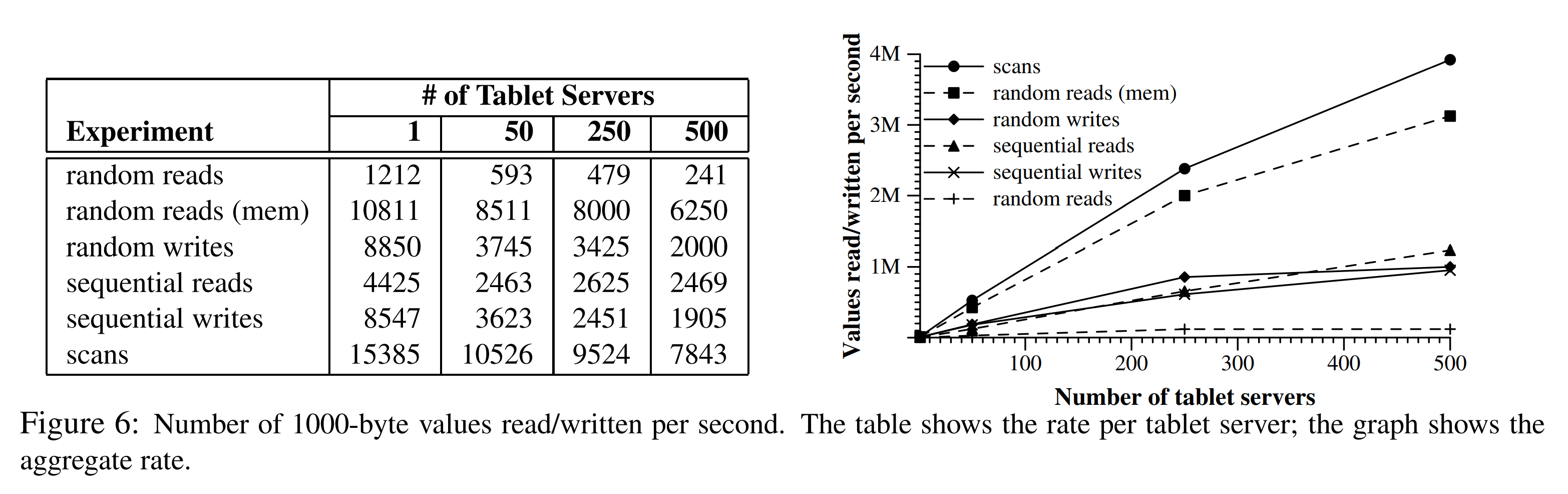{kind=link}
图6中展示了在Bigtable中读写1000字节的值的性能表现的两种视图。表中展示了每个tablet server每秒的操作数,图中展示了整体的每秒操作数。
让我们首先考虑单tablet server的性能表现。随机读取比所有其他操作要慢一个数量级或更多。每次随机读取中包含了将64KB的SSTable块通过网络从GFS发送到tablet server的操作,但其中仅有1000字节的值被使用。tablet server每秒执行约1200次读操作,读操作会从GFS以大概75MB/s的速率传输数据。由于网络栈的开销,这个带宽足以使tablet server的CPU饱和。SSTable的解析和Bigtable的代码,同样几乎是我们系统的网络连接饱和。大多数采用这种访问模式的Bigtable应用程序通常会将块大小减小到8KB。
内存式随机读取相比之下要快得多,因为tablet server的本地内存可以满足1000字节的读取,而不需要从GFS获取64KB的块。
随机写入和顺序写入的性能表现要biubiu随机读取更好,因为每个tablet server将所有到达的操作追加到到一个commit log中,并使用分组提交的方式,高效地将数据流式写入到GFS中。随机写入和顺序写入的性能表现没有太大的差距,在这两种亲情况下,tablet server所有的写入操作都会被记录到同一个commit log中。
顺序读取的性能表现比随机读取要好,因为每次从GFS获取的64KB的SSTable的块都会被存入块缓存中,在接下来的64次读取请求中都可以被使用。
扫描操作的性能甚至更高,因为tablet server可以在一次client的RPC中返回更多的值,因此RPC本身的开销可以被分摊到大量的值中。
当我们将系统中的tablet server数量从1个增加到500个时,整体的吞吐量增长非常显著,增长了100倍以上。例如,在tablet server的数量增长了500倍时,内存式随机读取的性能表现几乎增长了300倍。其原因在于该benchmark的性能瓶颈在于每台tablet server的CPU。
然而,性能表现并不是线性增长的。对于大多数的benchmark,当tablet server的数量从1个增加到50个时,每台tablet server的吞吐量会明显地下降。性能下降是由于多服务器配置的负载不均衡导致的,这通常由进程争夺CPU和网络导致。我们的负载均衡算法视图解决这种不均衡的问题,但是由于两个主要原因而无法完美解决:为了减少tablet的移动次数,我们减少了重均衡(当tablet被移动时,其会在通常小于1秒的短时间内不可用),且benchmark生成的负载会随着benchmark的进度变化。
随机读取benchmark的伸缩性最差(当服务器数量增加了500倍时整体吞吐量仅提升了100倍)。其原因在于每次读取1000字节的数据时都要传输较大的64KB的块。这种传输方式使网络中很多共享的1Gbps的网络链路饱和,这也导致了当增加机器数时每台server的吞吐量下降非常明显。
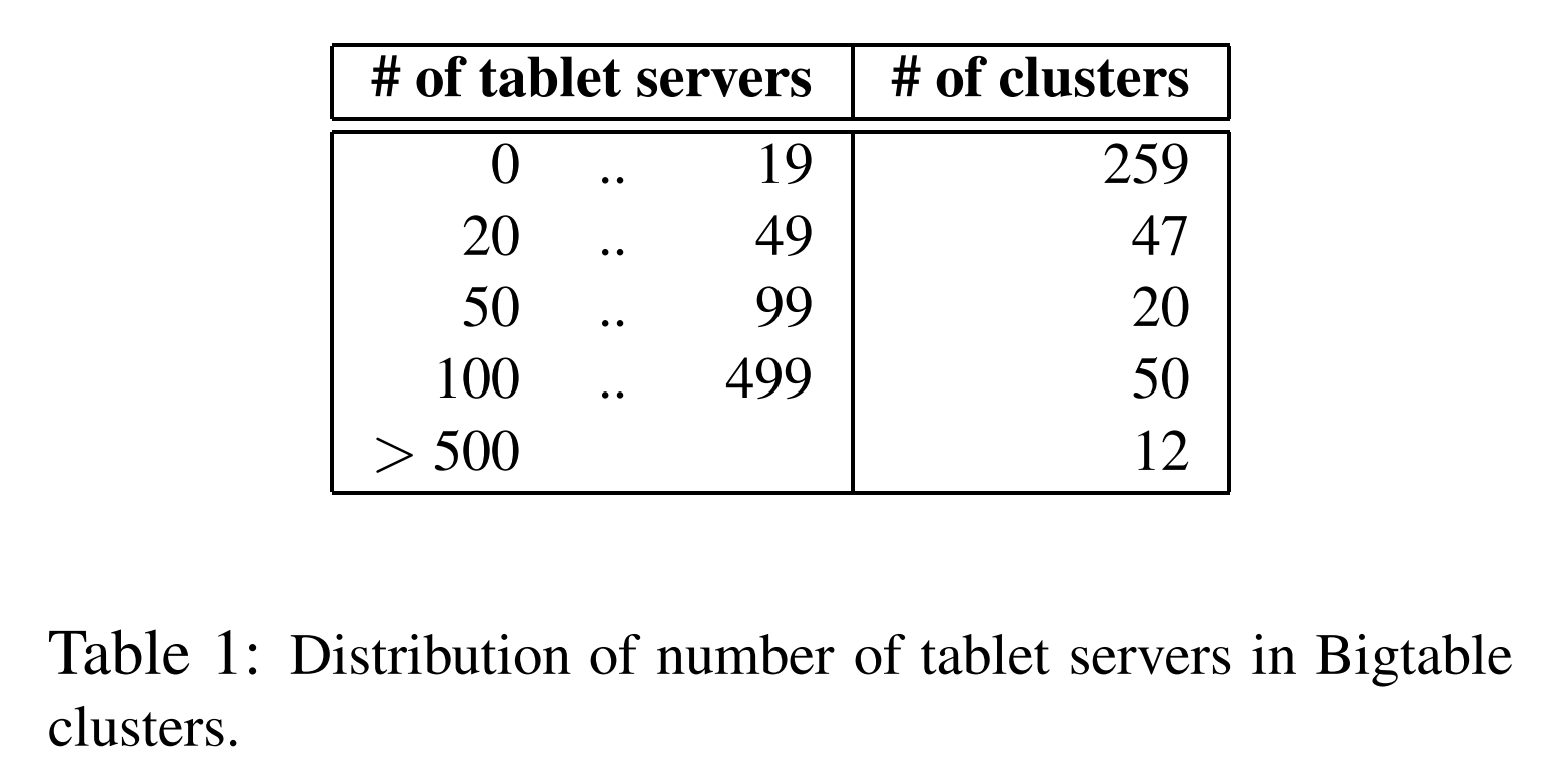
直到2006年8月,在Google的不同机器集群中共运行了388个非测试Bigtable集群,总计有24500台tablet server。表1中展示了每个cluster中tablet server的大致数量。其中许多集群被用作开发使用,因此在很长一段时间都是闲置的。一组由总计8069台tablet server组成的14个繁忙的集群每秒请求总量超过120万次,其以约741MB/s的速率收到RPC流量,以约16GB/s的速率发出RPC流量。
{kind=link}
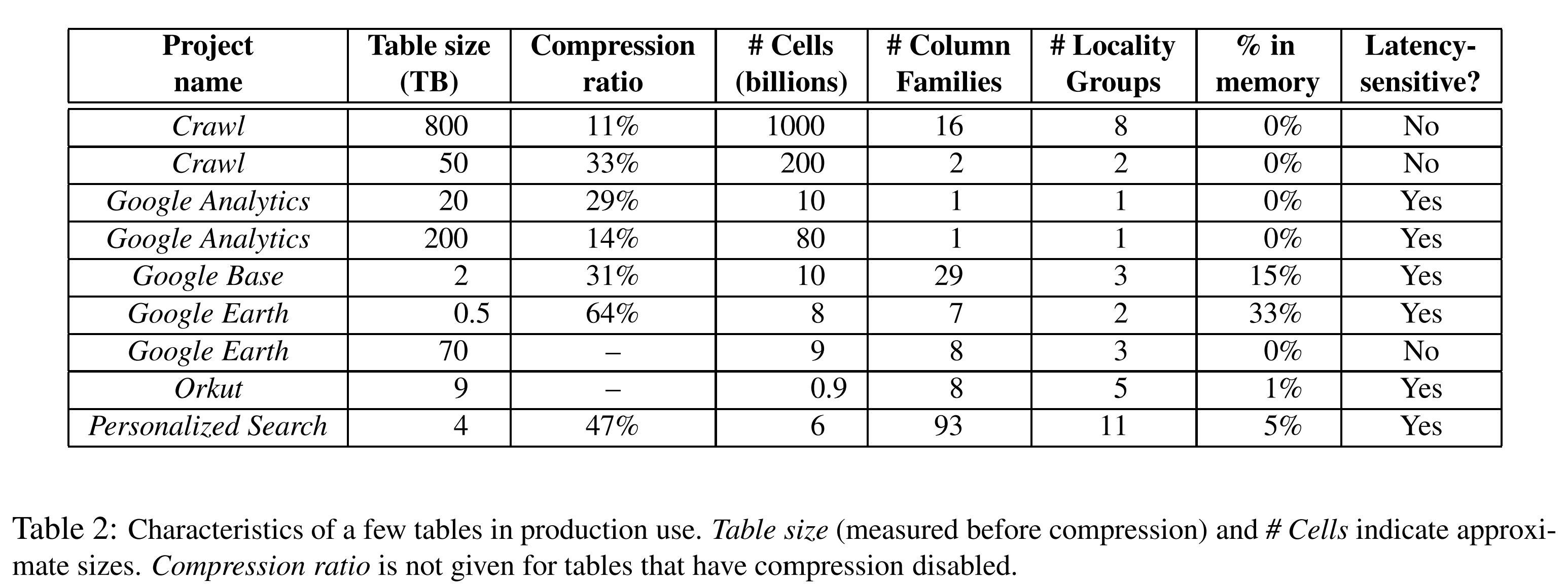
表2提供了一些目前正在使用的表的相关数据。其中一些表被用作存储用户数据,其他的一些表用于皮肤处。表的总大小、平均单元大小、服务中内存中数据使用百分比和表schema的复杂度丰富多变。在本章后续章节中,我们将简要描述三个生产团队如何使用Bigtable。
{kind=link}
Google Analytics(analytics.google.com)是一个用来帮助站长分析他们的流量模式的服务。其提供了整体分析,如每天里不同的访问者的数量、每个URL的网页每天的浏览量、和网站追踪分析报告等(如百分之多少的用户在浏览了指定的页面后购买了)。
为了启用该服务,站长需要将一小段JavaScript程序嵌入其前端页面。该程序会在网页被浏览时被调用。其记录了Google Analytics请求的各种信息,例如用户标识符和获取的网页信息。Google Analytics会汇总数据并让使其能被站长使用。
这里简要描述一下Google Analytic使用的两张表。raw click表(~200TB)的每一行都维护了一个终端用户的session。行名是包含网站名和session创建时间的元组。该schema确保了浏览相同网站的session是连续且按字典序排序的。该表被压缩到了其原始大小的14%。
summary表(~20TB)包含了各种网站预定义的总结。每隔一段时间,被调度的MapReduce任务会从raw click表计算生成summary表。每个MapReduce任务从raw click表中提取最近的session数据。整个系统的吞吐量受GFS的吞吐量限制。该表被压缩到了其原始大小的29%。
Google运营者一系列的服务。通过Google Maps接口(maps.google.com)和Google Earth(earth.google.com)自定义的client软件,这些服务让用户能够访问整个世界表面的高分辨率卫星图像。这些产品可以为用户提供整个世界表面的导航:它们可以在多种不同分辨率上计划、查看并注释卫星图像。该系统使用了一个表来预处理数据,并使用了另外一系列表为client提供数据服务。
预处理流水线使用了一张表来存储原始图像。在预处理中,图像会被清洗并合成为最终提供服务的数据。该表包含了约70TB的数据,因此其使用硬盘提供服务。这些图像已经被压缩过了,因此禁用了Bigtable的压缩。
图像表的每一行都对应一个地理段。行的命名保证了相邻的地理段被就近存储。表中包含了一个用来追踪每个段的数据源的列族。该列族中有大量的列,基本上每个原始数据图像都有一个列。由于每个地理段仅由少量几个图片构建出,因此该列族非常稀疏。
预处理流水线很大程度依赖MapReduce而不是Bigtable来传输数据。在一些MapReduce任务中,整个系统的每台tablet server数据处理速度超过1MB/s。
服务系统使用了一张表来索引存储在GFS中的数据。该表相对比较小(~500GB),但是其必须为每个数据中心的每秒数万次的查询提供低延时的服务。因此,该表分布在了上百台tablet server且使用了内存型列族。
个性化搜索(www.google.com/psearch)是一个可选的服务,其记录了用户在Google的各种产品如网页搜索、图片和新闻等上的的查询和点击。用户可以浏览他们的搜索历史以重新访问他们的历史查询和点击,同时他们还可以根据其Google历史使用模式进行个性化搜索。
个性化搜索在Bigtable中存储了每个用户的数据。每个用户都有一个唯一的userid,并有一个以这个userid命名的行。所有的用户行为都被存储在表中。每个用户的行为类型有一个独立的列族(例如,有一个列族存储了所有的web查询)。每个数据项在Bigtable中的时间戳为用户行为发生时间。个性化搜索会在Bigtable上使用MapReduce生成用户配置。这些用户配置文件被被用作实现个性化实时搜索结果。
个性化搜索的数据被被分到多个Bigtable集群中以增强可用性并减少因到client距离而带来的时延。个性化搜索团队原本在client侧建立了一个在Bigtable上层的副本机制以保证副本的最终一致性。而现在的系统目前使用的是构建在服务器端的副本子系统。
个性化搜索的存储系统的设计允许其他组在自己的列中添加新的用户的信息,目前Google的很多产品中都使用了该系统,它们需要存储每个用户的配置和设置。再多个组中共享同一张表导致该表中有不同寻常的大量的列族。为了支持这种共享,我们为Bigtable添加了一个简单的配额(quote)机制来限制任意一个client对共享表的存储消费。该机制为不同产品的组使用该系统存储每个用户的信息提供了一些隔离性。
在设计、实现、维护和支持Bigtable的过程中,我们收获了很多很有帮助的经验并学到了一些有趣的知识。
我们学到的一个知识是:大型分布式系统在很多种故障下是非常脆弱的,这些故障不仅仅包括标准的网络分区和很多分布式协议中假设的故障停机(fail-stop)问题。例如,我们遇到过所有以下原因导致的问题:内存和网络老化、较大的时钟偏差、机器挂起、扩展的和不对称的网络分区、我们使用的其他系统中的bug(如Chubby)、GFS配额溢出、有计划或无计划的硬件维护等。随着我们在这些问题上的经验越来越多,我们通过修改不同的协议来解决了这些问题。例如,我们在我们的RPC机制上增加了校验和。我们还通过移除系统中一个部分对另一个部分的假设解决了一些问题。例如,我们不再假设一个给定的Chubby操作仅能返回一组固定的错误中的一个。
我们学到的另一个知识是:等弄清楚一个新的特性会被怎样使用后再添加这个特性是非常重要的。例如,我们最初计划在我们的API中加入通用的事务控制。因为我们不需要立刻使用这一特性,所以我们没实现。现在,我们有很多真实的应用程序运行在Bigtable上,我们能够检验这些程序的实际需求。我们发现大部分应用程序仅需要单行的事务。当用户需要分布式事务时,最重要的用途是维护二级索引,我们计划添加一种装门用来满足这一需求的机制。新的机制将比分布式事务的通用性差,但是会更高效(特别是对于跨几百或更多行更新的时候)且好会和我们的乐观的(optimistic)跨数据中心备份方案配合的更好。
在我们为Bigtable提供支持时学到的重要的知识是:合适的系统级监控的重要性(即同时监控Bigtable自身和通过Bigtable监控client进程)。例如,我们扩展了我们的RPC系统,使我们可以记录样例RPC的一个样例在整个RPC过程中的重要行为。这一特性让我们能够检测并修复很多问题,如tablet数据结构中的锁争用、提交Bigtable变更时GFS的写入慢、当METADATA tablet不可用时对METADATA表的访问会被卡主等。另一个体现了监控的用处的例子是:每个Bigtable都会在Chubby中注册。这让我们能够追踪所有的集群、发现集群大小、查看集群中运行的软件版本、查看集群正在接受的流量、有没有出现意外的长延时等。
我们学到的最重要的知识是简单的设计的价值。考虑到我们系统的大小(不包括测试大概有10万行代码)和代码会随着时间无法预料的变化,我们发现代码和设计的清晰对代码维护和调试有巨大的帮助。其中一个例子是我们的tablet server成员协议。我们的最初的协议非常简单:master每隔一段时间会向tablet server发出租约,如果tablet server的租约过期,它们会杀死自己的进程。不幸的是,这个协议会在出现网络故障时大大削弱系统的可用性,同时该协议对master的恢复时间非常敏感。我们重新设计了几次协议,知道我们得到了一个表现良好的协议。然而,最终的协议太过复杂并依赖Chubby中很少被其他应用程序使用的特性。我们发现我们花费了过多的时间在Bigtable的代码中甚至在Chubby的代码中调试模糊的情况。最终,我们不再使用该协议并转向了新的更简单的协议,新的协议仅依赖Chubby中被广泛应用的的特性。
项目Boxwood[24]中有与Chubby、GFS和Bigtable在某些方面功能重叠的组件,其提供了分布式协议、锁、分布式块(chunk)存储、和分布式B树存储。虽然Boxwood在这些方面都有重叠,但其组件的目标定位似乎比Google的服务要较底层。Boxwood项目的目标是提供构建高层服务(如文件系统或数据库)的基础设施,而Bigtable的目标是直接支持client应用程序的数据存储需求。
许多近期的项目都解决了提供分布式存储或在广域网下(通常在Internet的范围下)提供高层服务的问题。包括从CAN[29]、Chord[32]、Tapestry[37]和Pastry[30]之类的项目开始的分布式哈希表的工作。这些系统解决了在Bigtable中不会出现的问题,如高度可变的带宽、不受信的参与者、频繁地修改配置等。去中心化的控制和拜占庭容错不是Bigtable的目标。
我们认为对于应用程序开发者来说,分布式的B树或分布式哈希表的模型过于受限。键值对的模型是十分有用的构建模块,但我们也不应该仅向开发者提供这一种模块。我们选择的模型比普通的键值对更加丰富,且支持稀疏的半结构化数据。而且该模型仍保持的足够的简单性,可用于非常高效的扁平化的文件表示;且其足够透明(通过局部组),用户可以对系统的重要行为进行调优。
一些数据库的供应商已经开发了能够存储大量数据的并行数据库。Oracle的Real Application Cluster数据库[27]使用了共享磁盘来存储数据(Bigtable使用GFS)并使用一个分布式的锁管理器(Bigtable使用Chubby)。IBM的DB2 Parallel Edition[4]基于类似Bigtable的shared-nothing[33]架构。每个DB2服务器负责管理一张表的行的一个子集,这个子集被存储在本地的关系型数据库中。这两个产品都提供了带事务的完整的关系模型。
相比于其他在磁盘上基于列而不是基于行组织数据的存储系统(包括C-Store[1, 34]和商业产品如Sybase IQ[15, 36]、Sensage[31]、KDB+[22]和MonetDB/X100的ColumnBM存储层[38]),Bigtable的局部组实现了类似的压缩和磁盘读优化。另一个可以将数据横向或纵向分区到扁平化的文件中并有良好压缩率的系统是AT&T的Daytona数据库[19]。Bigtable的局部组不支持CPU缓存级别的优化,如Ailamaki[2]中描述的那种优化。
Bigtable使用memtable和SSTable将更新存储到tablet的方式与Log-Structured Merge Tree[26]中将更新存储到索引数据中的方式类似。在二者中,排好序的数据在写入磁盘前都会在内存中缓冲,读操作必须合并内存和磁盘中的数据。
C-Store和Bigtable有很多相同的特性:二者都使用shared-nothing架构,且都有两种不同的数据结构,其中之一被最近的写入使用,另一个用来长期存储数据,并有将数据从一种格式转移到另一种格式的方法。但这连个系统的API有着很大的区别:C-Store像是一个关系型数据库,而Bigtable提供了较为底层的读写接口且被设计支持每台服务器每秒钟处理几千个这种请求。C-Store还是一个有读优化的关系型DBMS,而Bigtable为读敏感和写敏感的应用程序都提供了很好的性能。
Bigtable的负载均衡器解决了一些在同类型的shared-nothing数据库的负载均衡和内存均衡问题(例如参考文献[11, 35])。我们的问题与之相比更简单一些:(1)我们不需要考虑可能由于视图或索引导致的相同数据有多个副本的情况;(2)我们让用户界定数据应该存储在内存中还是在磁盘中昂,而不是试图自动地为其做决策;(3)我们不需要执行或优化复杂的查询。
我们描述了Bigtale,其是一个Google中用来存储结构化数据的分布式系统。Bigtable集群从2005年4月开始一直使用至今,我们在那之前大概花费了7人年的时间来设计并实现它。知道2006年8月,已经有超过60个项目使用了Bigtable。我们的用户喜欢Bigtable的实现提供了性能和高可用性,也因此用户可以在资源需求随时间变化时能够简单地通过在系统中添加更多机器的方式来提高集群的容量。
考虑到Bigtable的接口不太常见,我们的用户适配该系统的难度也是一个有趣的问题。新用户有时不确定怎样使用Bigtable的接口才能获得最好的效果,特别是当他们习惯使用支持通用事务的关系型数据库时。不过,事实上Google中使用Bigtable的很多产品的成功印证了在实际环境中我们的设计非常良好。
我们正在实现一些Bigtable的额外的特性,比如支持二级索引和构建具有多master副本的跨数据中心备份的Bigtable的基础设施。我们还开始将Bigtable作为产品服务部署,这样独立的团队就不需要维护自己的集群。随着我们的服务集群变大,我们需要解决更多Bigtable自身的资源共享问题[3, 5]。
最后,我们发现在Google构建自己的存储方案有很大的优势。在为Bigtable设计自己的数据模型时,我们有很大的灵活性。此外,我们对Bigtable实现的控制权和对Bigtable依赖的其他Google的基础设施的控制权意味着当效率低下时我们能够移除性能瓶颈。
感谢匿名的审稿者、David Nagle和我们的领导者Brad Calder为本篇论文提供的反馈。Bigtable系统收到了很多Google内用户的反馈。另外,感谢以下的人为Bigtable做出的贡献:Dan Aguayo、Sameer Ajmani、Zhifeng Chen、Bill Coughran、Mike Epstein、Healfdene Goguen、Robert Griesemer、Jeremy Hylton、Josh Hyman、Alex Khesin、Joanna Kulik、Alberto Lerner、Sherry Listgarten、Mike Maloney、Eduardo Pinheiro、Kathy Polizzi、Frank Yellin、Arthur Zwiegincew。
[1] ABADI, D. J., MADDEN, S. R., AND FERREIRA, M. C. Integrating compression and execution in columnoriented database systems. Proc. of SIGMOD (2006).
[2] AILAMAKI, A., DEWITT, D. J., HILL, M. D., AND SKOUNAKIS, M. Weaving relations for cache performance. In The VLDB Journal (2001), pp. 169–180.
[3] BANGA, G., DRUSCHEL, P., AND MOGUL, J. C. Resource containers: A new facility for resource management in server systems. In Proc. of the 3rd OSDI (Feb. 1999), pp. 45–58.
[4] BARU, C. K., FECTEAU, G., GOYAL, A., HSIAO, H., JHINGRAN, A., PADMANABHAN, S., COPELAND, G. P., AND WILSON, W. G. DB2 parallel edition. IBM Systems Journal 34, 2 (1995), 292–322.
[5] BAVIER, A., BOWMAN, M., CHUN, B., CULLER, D., KARLIN, S., PETERSON, L., ROSCOE, T., SPALINK, T., AND WAWRZONIAK, M. Operating system support for planetary-scale network services. In Proc. of the 1st NSDI (Mar. 2004), pp. 253–266.
[6] BENTLEY, J. L., AND MCILROY, M. D. Data compression using long common strings. In Data Compression Conference (1999), pp. 287–295.
[7] BLOOM, B. H. Space/time trade-offs in hash coding with allowable errors. CACM 13, 7 (1970), 422–426.
[8] BURROWS, M. The Chubby lock service for looselycoupled distributed systems. In Proc. of the 7th OSDI (Nov. 2006).
[9] CHANDRA, T., GRIESEMER, R., AND REDSTONE, J. Paxos made live — An engineering perspective. In Proc. of PODC (2007).
[10] COMER, D. Ubiquitous B-tree. Computing Surveys 11, 2 (June 1979), 121–137.
[11] COPELAND, G. P., ALEXANDER, W., BOUGHTER, E. E., AND KELLER, T. W. Data placement in Bubba. In Proc. of SIGMOD (1988), pp. 99–108.
[12] DEAN, J., AND GHEMAWAT, S. MapReduce: Simplified data processing on large clusters. In Proc. of the 6th OSDI (Dec. 2004), pp. 137–150.
[13] DEWITT, D., KATZ, R., OLKEN, F., SHAPIRO, L., STONEBRAKER, M., AND WOOD, D. Implementation techniques for main memory database systems. In Proc. of SIGMOD (June 1984), pp. 1–8.
[14] DEWITT, D. J., AND GRAY, J. Parallel database systems: The future of high performance database systems. CACM 35, 6 (June 1992), 85–98.
[15] FRENCH, C. D. One size fits all database architectures do not work for DSS. In Proc. of SIGMOD (May 1995), pp. 449–450.
[16] GAWLICK, D., AND KINKADE, D. Varieties of concurrency control in IMS/VS fast path. Database Engineering Bulletin 8, 2 (1985), 3–10.
[17] GHEMAWAT, S., GOBIOFF, H., AND LEUNG, S.-T. The Google file system. In Proc. of the 19th ACM SOSP (Dec. 2003), pp. 29–43.
[18] GRAY, J. Notes on database operating systems. In Operating Systems — An Advanced Course, vol. 60 of Lecture Notes in Computer Science. Springer-Verlag, 1978.
[19] GREER, R. Daytona and the fourth-generation language Cymbal. In Proc. of SIGMOD (1999), pp. 525–526.
[20] HAGMANN, R. Reimplementing the Cedar file system using logging and group commit. In Proc. of the 11th SOSP (Dec. 1987), pp. 155–162.
[21] HARTMAN, J. H., AND OUSTERHOUT, J. K. The Zebra striped network file system. In Proc. of the 14th SOSP (Asheville, NC, 1993), pp. 29–43.
[22] KX.COM. kx.com/products/database.php. Product page.
[23] LAMPORT, L. The part-time parliament. ACM TOCS 16, 2 (1998), 133–169.
[24] MACCORMICK, J., MURPHY, N., NAJORK, M., THEKKATH, C. A., AND ZHOU, L. Boxwood: Abstractions as the foundation for storage infrastructure. In Proc. of the 6th OSDI (Dec. 2004), pp. 105–120.
[25] MCCARTHY, J. Recursive functions of symbolic expressions and their computation by machine. CACM 3, 4 (Apr. 1960), 184–195.
[26] O’NEIL, P., CHENG, E., GAWLICK, D., AND O’NEIL, E. The log-structured merge-tree (LSM-tree). Acta Inf. 33, 4 (1996), 351–385.
[27] ORACLE.COM. www.oracle.com/technology/products/- database/clustering/index.html. Product page.
[28] PIKE, R., DORWARD, S., GRIESEMER, R., AND QUINLAN, S. Interpreting the data: Parallel analysis with Sawzall. Scientific Programming Journal 13, 4 (2005), 227–298.
[29] RATNASAMY, S., FRANCIS, P., HANDLEY, M., KARP, R., AND SHENKER, S. A scalable content-addressable network. In Proc. of SIGCOMM (Aug. 2001), pp. 161–172.
[30] ROWSTRON, A., AND DRUSCHEL, P. Pastry: Scalable, distributed object location and routing for largescale peer-to-peer systems. In Proc. of Middleware 2001 (Nov. 2001), pp. 329–350.
[31] SENSAGE.COM. sensage.com/products-sensage.htm. Product page.
[32] STOICA, I., MORRIS, R., KARGER, D., KAASHOEK, M. F., AND BALAKRISHNAN, H. Chord: A scalable peer-to-peer lookup service for Internet applications. In Proc. of SIGCOMM (Aug. 2001), pp. 149–160.
[33] STONEBRAKER, M. The case for shared nothing. Database Engineering Bulletin 9, 1 (Mar. 1986), 4–9.
[34] STONEBRAKER, M., ABADI, D. J., BATKIN, A., CHEN, X., CHERNIACK, M., FERREIRA, M., LAU, E., LIN, A., MADDEN, S., O’NEIL, E., O’NEIL, P., RASIN, A., TRAN, N., AND ZDONIK, S. C-Store: A columnoriented DBMS. In Proc. of VLDB (Aug. 2005), pp. 553–564.
[35] STONEBRAKER, M., AOKI, P. M., DEVINE, R., LITWIN, W., AND OLSON, M. A. Mariposa: A new architecture for distributed data. In Proc. of the Tenth ICDE (1994), IEEE Computer Society, pp. 54–65.
[36] SYBASE.COM. www.sybase.com/products/databaseservers/sybaseiq. Product page.
[37] ZHAO, B. Y., KUBIATOWICZ, J., AND JOSEPH, A. D. Tapestry: An infrastructure for fault-tolerant wide-area location and routing. Tech. Rep. UCB/CSD-01-1141, CS Division, UC Berkeley, Apr. 2001.
[38] ZUKOWSKI, M., BONCZ, P. A., NES, N., AND HEMAN, S. MonetDB/X100 — A DBMS in the CPU cache. IEEE Data Eng. Bull. 28, 2 (2005), 17–22.